R
è un programma per la analisi statistica e grafica dei dati e la cosa che accade con maggior frequenza è avere dei dati gestiti esternamente a R, in un database o in
un foglio elettronico, e volerli importare in R
per poterli analizzare.
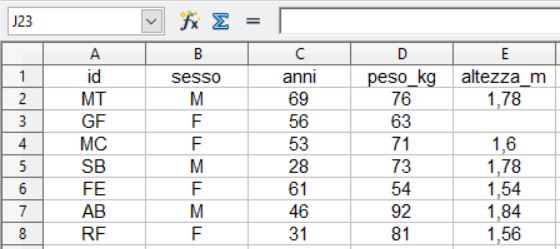
Una
struttura dati tipica, ed estesamente impiegata anche in R
[1], è riportata in questa tabella (che è di fatto un
minuscolo database)

nella
quale le cose da notare in relazione a R sono abbastanza
semplici:
→ le
righe corrispondono ai casi della statistica (e ai record del
database);
→ le
colonne corrispondono alle variabili della statistica (e ai campi
del database);
→ i
nomi delle variabili sono riportati nella prima riga (in
R sono facoltativi ma
fortemente raccomandati per mantenere ordine e chiarezza nel proprio
lavoro);
→ le
variabili possono essere sia numeriche, sia qualitative (per
esempio qui Sesso è una variabile qualitativa);
→ un
identificativo
univoco
di ciascuno dei casi
può essere riportato nella prima
colonna (è facoltativo). Se l’identificativo non è presente nei
dati originali R
numera automaticamente i casi
in ordine crescente per identificare ciascun caso in modo univoco;
→ dato
che come separatore delle cifre decimali R al proprio interno impiega esclusivamente il punto (.) se nei dati da importare viene impiegata
la virgola (,) questa verrà convertita da R
in un punto (.);
→ è
possibile che si verifichi la mancanza
di dati,
per esempio qui manca il valore di
Altezza nel
caso
GF,
e il campo è quindi vuoto. R
al momento di importare i dati riconoscerà automaticamente questi casi riportando nel campo del dato mancante la sigla NA
ovvero Not
Available;
Nota bene: in R
le variabili qualitative, non numeriche, sono denominate fattori e sono importanti in quanto
consentono di raggruppare i dati di una database in sottoinsiemi. Così i dati della nostra tabella potranno
essere elaborati tutti insieme o suddivisi in due gruppi in base al
valore assunto dalla variabile Sesso. Ovviamente è indispensabile
che la variabile in base alla quale i dati possono essere raggruppati
sia codificata in modo rigoroso, così il sesso maschile, poiché R riconosce lettere maiuscole e lettere minuscole, deve essere
espresso sempre con
M
(o
con
m)
e
non si
possono usare
M
o
m
indifferentemente.
Il
tema che si pone con R
è ora questo: in quale formato salvare (e leggere) i dati?
Abbiamo visto altrove che il modo migliore per salvare uno script [2] è farlo in un file
di testo (in genere con estensione .txt ma in R anche con estensione .R) nel quale i caratteri
possono essere scritti (e successivamente essere riletti) in
chiaro
nello stesso modo in cui sono scritti su (e possono essere riletti
da) un foglio di carta scritto con una macchina da scrivere [3],
impiegando un set di caratteri limitato, ma universalmente
riconosciuto, tipicamente il codice ASCII di base [4].
La
stessa identica soluzione - salvarli in un file di
testo nel quale sono scritti in chiaro - è raccomandata per i dati e impiega il formato .csv
(l'acronimo
csv sta per
comma separated values cioè
per valori separati dalla virgola (,) tuttavia come vedremo tra poco
il separatore di campo può essere anche un altro carattere). Le modalità per salvare in formato .csv i dati dipendono dal programma sul quale risiedono e dal quale li volete esportare, ora invece vediamo come li possiamo leggere e importare in R.
Per continuare è necessario:
→
effettuare
il
download del
file
importa_csv.csv
→ salvare
il file nella cartella C:\Rdati\
Per questo e gli altri file di dati impiegati nei post trovate link e modalità di download alla pagina Dati.
Il
file, aperto con un editor di testo come ad esempio il Blocco
note di Windows, contiene i dati della tabella/database:
id;sesso;anni;peso_kg;altezza_m
MT;M;69;76;1,78
GF;F;56;63;
MC;F;53;71;1,60
SB;M;28;73;1,78
FE;F;61;54;1,54
AB;M;46;92;1,84
RF;F;31;81;1,56
Come
vedete un file
.csv è,
analogamente a un file
.txt,
un file di testo scritto in chiaro con caratteri standard e in cui i dati sono organizzati con regole molto semplici e immediatamente riconoscibili
semplicemente aprendo il file con un qualsiasi editor di testo (ed è
esattamente questo il punto di forza del formato .csv).
In
un tipico file .csv come
questo:
→ nella
prima riga sono riportati i nomi delle variabili ovvero dei campi che compongono i
record;
→ nelle
righe successive alla prima sono riportati, uno per riga, i casi ovvero i record
che compongono il database;
→ il
punto e virgola (;) è il separatore di campo che indica la
fine di un campo e il passaggio al campo successivo;
→ come
separatore delle cifre
decimali è impiegata la
virgola (,);
→ il fatto che la prima colonna/variabile debba essere interpretata come una variabile qualsiasi piuttosto che come un identificativo univoco di ciascun record/caso viene specificato nel momento in cui sono importati i dati (vedere qui sotto);
→ nel caso GF abbiamo un dato mancante, quello dell'altezza.
L'impiego
del punto e virgola (;) come separatore di campo e della virgola (,)
come separatore delle cifre decimali non è casuale. Il file
importa_csv.csv è stato generato salvando in formato
.csv i dati contenuti in un foglio elettronico
che
è lo strumento più frequentemente impiegato per gestire i propri
dati [53]. Il punto e virgola (;) come
separatore di campo e la virgola (,) come separatore delle cifre decimali
sono impostati di default in Windows nei paesi come Spagna, Italia e
Francia, e il foglio elettronico nel nostro caso ha salvato il
file .csv impiegando la configurazione di Windows [nei paesi
anglosassoni in Windows sono impostati di default la virgola (,) come
separatore di campo e il punto (.) come separatore delle cifre
decimali].
Ora
copiate e incollate nella Console
di R questo
script
e premete ↵
Invio:
#
IMPORTA I DATI DI UN FILE CSV
#
notare / invece di \ su windows
mydata
<- read.table("C:/Rdati/importa_csv.csv", header=TRUE,
sep=";", dec=",")
#
All'oggetto
mydata
viene assegnato (<-)
il contenuto importato dalla funzione read.table() [6]. Gli argomenti della funzione, racchiusi nella parentesi, specificano
che:
→ il
file dal quale importare i dati è C:/R/importa_csv.csv;
→ la
prima riga nel file è una riga di intestazione con i nomi delle
variabili (header=TRUE);
→ nel
file è impiegato come separatore di campo il punto e virgola
(sep=";");
→ nel
file è impiegato come separatore delle cifre decimali la virgola (dec=",").
Se ora nella Console di R digitate
mydata
vedete
comparire i dati che avete appena importato:
> mydata
id sesso anni peso_kg altezza_m
1 MT M 69 76 1.78
2 GF F 56 63 NA
3 MC F 53 71 1.60
4 SB M 28 73 1.78
5 FE F 61 54 1.54
6 AB M 46 92 1.84
7 RF F 31 81 1.56
Notate
che:
→ dalla tabella/database importa_csv.csv sono stati importati 7 record/casi ciascuno contenente cinque campi/variabili (id, sesso, anni, peso_kg, altezza_m);
→ R
ha aggiunto a ciascuno dei casi un identificativo univoco sotto forma di un
numero progressivo (1
per la prima riga/caso,
2 per la seconda riga/caso, e così via);
→ la virgola (,) presente come separatore delle cifre decimali nei dati originali è stata automaticamente trasformata da R in un punto (.).
Se
avessimo deciso che nel campo “id” è contenuto l'identificativo univoco di ciascun caso avremmo dovuto eseguire quest'altro script:
#
IMPORTA I DATI DI UN FILE CSV CON IDENTIFICATIVO UNIVOCO DEI CASI
#
notare / invece di \ su windows
mydata
<- read.table("C:/Rdati/importa_csv.csv", header=TRUE,
sep=";", dec=",", row.names="id")
#
Rispetto
al precedente script, alla funzione read.table() è stato aggiunto l'argomento row.names="id"
mediante il quale viene specificato che come identificativo di ciascuna riga/caso deve essere impiegato il campo
id. In questo modo R:
→ dalla tabella/database importa_csv.csv importerà 7 record ciascuno contenente quattro campi/variabili (sesso, anni, peso_kg, altezza_m);
→ assocerà a ciascuno dei casi l'identificativo univoco contenuto nel campo id.
Se
ora nella Console
di R digitate
mydata
vedete che R non ha più assegnato ai casi l'identificativo numerico (1, 2, ...) previsto di default, ma che ciascuna riga/caso è stato identificato in modo univoco mediante il valore contenuto nel campo id (MT per il primo caso/record, GF per il secondo caso/record, e così via):
> mydata
sesso anni peso_kg altezza_m
MT M 69 76 1.78
GF F 56 63 NA
MC F 53 71 1.60
SB M 28 73 1.78
FE F 61 54 1.54
AB M 46 92 1.84
RF F 31 81 1.56
A questo punto ecco la domanda che sarà venuta in mente a tutti: cosa accade se due casi/record per errore hanno lo stesso identificativo, quindi se il campo specificato in realtà non contiene un identificativo univoco?
Supponiamo che tabella/database importa_csv.csv contenga questi dati (il primo e il terzo caso hanno ora lo stesso identificativo MT):
id;sesso;anni;peso_kg;altezza_m
MT;M;69;76;1,78
GF;F;56;63;
MT;F;53;71;1,60
SB;M;28;73;1,78
FE;F;61;54;1,54
AB;M;46;92;1,84
RF;F;31;81;1,56
In questo caso questa ecco la risposta che comparirebbe nella Console di R:
Error in read.table("C:/Rdati/importa_csv.csv", header = TRUE, sep = ";", dec = ",", :
duplicate 'row.names' are not allowed
Quindi R non importa i dati e ci viene in aiuto in modo che non possiamo sbagliare su un aspetto così critico.
Dato
che l'importazione dei dati è un punto di svolta nell'apprendimento
di R,
si consiglia di familiarizzare adeguatamente con questo aspetto
adattando gli script qui riportati a file
.csv contenenti
propri dati.
Chi desidera importare i dati direttamente da file .xls o .xlsx può consultare il post Importazione dei dati da un file .xls o .xlsx.
----------
[1]
In alcuni pacchetti di R possono essere richieste strutture
dati differenti, che sono peraltro specificate e illustrate nei
manuali di riferimento dei pacchetti che le richiedono.
[2] Vedere il post Salvare uno script.
[3] Macchina da scrivere oramai da tempo soppiantata, ma è da qui che è
originato il concetto che, passando per la telescrivente, è stato applicato a PC e stampante.
[4] Vedere il post Codifica dei caratteri ASCII, ANSI, Unicode (UTF).
[3] Non mi dilungo ulteriormente su questo punto in quanto qualsiasi foglio elettronico e qualsiasi database consente con una voce del menù tipo Esporta... o tipo Salva con nome... di esportare i dati in formato .csv
[4] Digitate help(read.table) nella Console di R per la documentazione della funzione read.table().