Il formato dati
raccomandato di R è il formato .csv e consente prima dell'importazione una ispezione preliminare dei
dati, che sono accessibili in chiaro, semplicemente aprendo il file
.csv con un editor di testo.
I
formati
.xls
e
.xlsx
sono invece formati binari, nei quali i dati non sono accessibili in chiaro, e
non
sono formati standardizzati per cui la struttura dei file potrebbe cambiare
senza preavviso nelle nuove versioni
dei programmi che salvano in questi formati, causando
errori imprevedibili e pertanto non gestibili nell’importazione dei
dati in R [1]. Nonostante questo, data la larga diffusione dei dati salvati in
questi formati, in R
si trovano pacchetti che consentono di importare i dati direttamente
da file
.xls
e
.xlsx
come
ad esempio il pacchetto
xlsx
che
si può scaricate dal CRAN
(Comprehensive
R
Archive
Network)
selezionando nel menù
Pacchetti
di
R
l’opzione
Installa
pacchetti…
e
quindi selezionando
xlsx
dall’elenco
dei pacchetti disponibili.
Per
la documentazione completa del pacchetto
xlsx
vedere il suo
manuale di riferimento [2].
Se nel menù
Aiuto di
R selezionate
Guida Html nella
sezione
Reference alla voce
Packages
trovate la
documentazione dei pacchetti che avete installato sul vostro PC o
notebook e che include, però in una versione meno completa, la
documentazione del pacchetto
xlsx.
Potete anche digitare help(read.xlsx)
nella
Console di R per
una documentazione concisa ed essenziale della funzione read.xlsx().
Per
proseguire ora è necessario:
→
effettuare
il
download del
file
importa_xls.xls
→
effettuare
il
download del
file
importa_xlsx.xlsx
→ salvare
i file nella cartella C:\Rdati\
Per questo e gli altri file di dati impiegati nei post trovate link e modalità di download alla pagina Dati.
Copiate
e incollate nella
Console
di R
questo
script
e premete
↵
Invio:
#
IMPORTA I DATI DI UN FILE XLS
#
#
carica il pacchetto xlsx
require(xlsx)
#
carica nell'oggetto mydata i dati del file e del foglio specificati,
notare / invece di \ su windows
mydata
<- read.xlsx("C:/Rdati/importa_xls.xls",
sheetName="peso_altezza")
#
La funzione require() carica in R il pacchetto xlsx contenente la funzione read.xlsx() che permette di importare i dati.
Gli unici argomenti richiesti dalla funzione read.xlsx() sono il nome del file con il percorso completo ("C:/Rdati/importa_xls.xls") e il nome del foglio che contiene i dati (sheetName="peso_altezza") all’interno del file. Quest'ultimo argomento è cruciale in quanto permette di gestire i molteplici fogli che possono essere presenti all'interno di un unico file .xls o xlsx.
Gli unici argomenti richiesti dalla funzione read.xlsx() sono il nome del file con il percorso completo ("C:/Rdati/importa_xls.xls") e il nome del foglio che contiene i dati (sheetName="peso_altezza") all’interno del file. Quest'ultimo argomento è cruciale in quanto permette di gestire i molteplici fogli che possono essere presenti all'interno di un unico file .xls o xlsx.
Se
ora digitate mydata
e premete
↵
Invio
potete
scorrere nella
Console
di R
i
dati che sono stati importati:
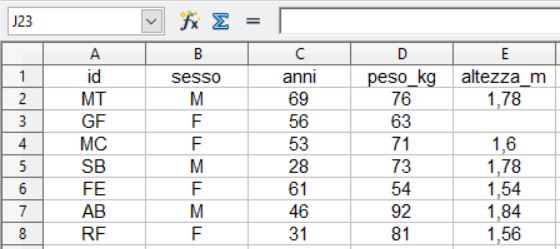
> mydata
id sesso anni peso_kg altezza_m
1 MT M 69 76 1.78
2 GF F 56 63 NA
3 MC F 53 71 1.60
4 SB M 28 73 1.78
5 FE F 61 54 1.54
6 AB M 46 92 1.84
7 RF F 31 81 1.56
id sesso anni peso_kg altezza_m
1 MT M 69 76 1.78
2 GF F 56 63 NA
3 MC F 53 71 1.60
4 SB M 28 73 1.78
5 FE F 61 54 1.54
6 AB M 46 92 1.84
7 RF F 31 81 1.56
Per
avere la conferma del fatto che i dati sono stati importati
correttamente confrontateli con l’originale aprendo il file con
Excel o in
alternativa con un programma appartenente alla categoria del software
libero [3] come
OpenOffice calc o
LibreOffice calc. La sola differenza che riscontrerete risiederà nel separatore dei
decimali, che nel foglio elettronico vedrete essere (nella
configurazione italiana di Windows) la virgola (,) mentre nei dati
importati trovate il punto (.) che è il separatore delle cifre
decimali impiegato da R.
Notare che R assegna automaticamente un identificativo univoco numerico (1, 2, eccetera) ai casi/righe.
Per importare un file .xlsx copiate
e incollate nella
Console
di R
questo
script
e premete
↵
Invio:
#
IMPORTA I DATI DI UN FILE XLSX
#
#
carica il pacchetto xlsx
require(xlsx)
#
carica nell'oggetto mydata i dati del file e del foglio specificati,
notare / invece di \ su windows
mydata
<- read.xlsx("C:/Rdati/importa_xlsx.xlsx",
sheetName="peso_altezza", row.names="id")
#
Questa
volta l'argomento row.names="id"
specifica che gli identificativi univoci dei casi sono contenuti nel campo
id del
file. Se ora digitate mydata
e premete
↵
Invio
potete
scorrere nella
Console
di R
i
dati che sono stati importati
>
mydata
sesso anni peso_kg altezza_m
MT M 69 76 1.78
GF F 56 63 NA
MC F 53 71 1.60
SB M 28 73 1.78
FE F 61 54 1.54
AB M 46 92 1.84
RF F 31 81 1.56
MT M 69 76 1.78
GF F 56 63 NA
MC F 53 71 1.60
SB M 28 73 1.78
FE F 61 54 1.54
AB M 46 92 1.84
RF F 31 81 1.56
nei quali l'identificativo univoco numerico di R non compare più, essendo stato sostituito da quello già presente nei dati importati.
Importare in R file .xls e .xlsx salvati con un foglio elettronico è quindi semplice. Tuttavia si ricorda che qualsiasi foglio elettronico è in grado di salvare i dati anche in formato .csv e che è questo il formato raccomandato da R (vedere il post Importazione dei dati da un file .csv).
----------
https://cran.r-project.org/doc/manuals/r-release/R-data.pdf
[2]
xlsx:
Read, Write, Format Excel 2007 and Excel 97/2000/XP/2003 Files.
https://cran.r-project.org/web/packages/xlsx/index.html
[3] Per il significato di Software
libero,
di Software
open source
e di Software
di dominio pubblico
vedere: The
Free Software Foundation. GNU Operating System. Categories of free
and nonfree software.
https://www.gnu.org/philosophy/categories.en.html