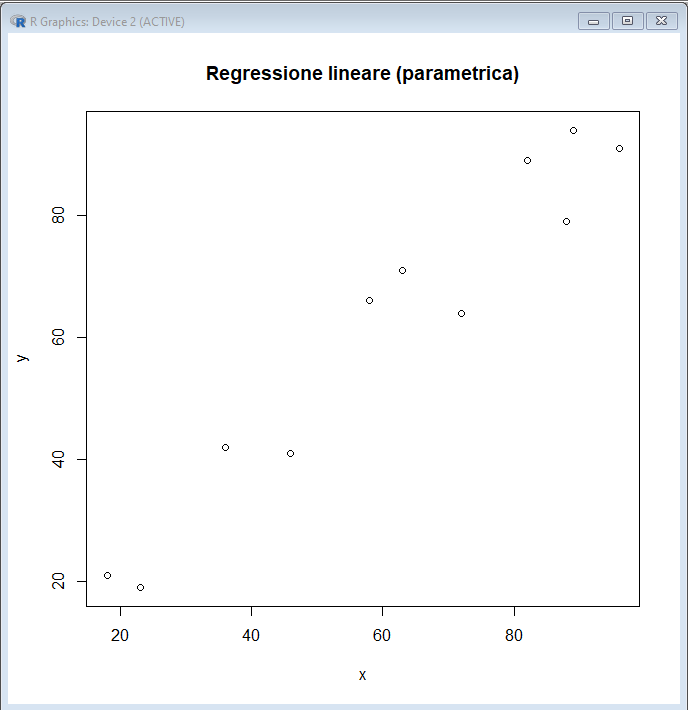
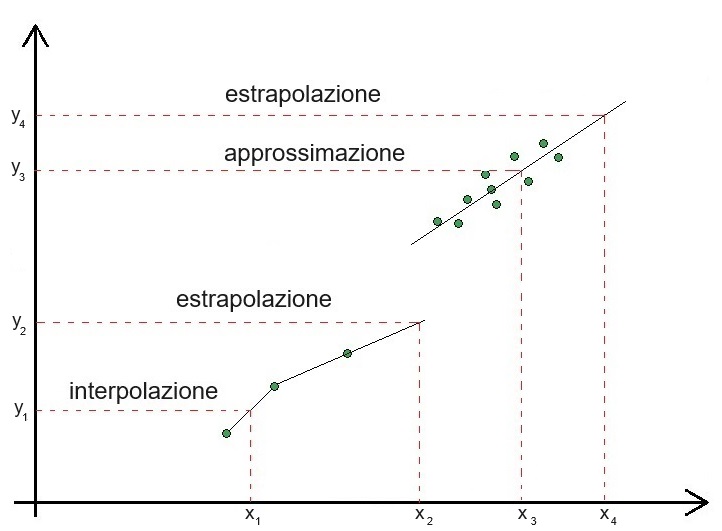
Data una serie di valori su un piano cartesiano, il valore della variabile dipendente y corrispondente ad uno specifico valore della variabile indipendente x può essere ricavato mediante:
→ interpolazione quando può essere calcolato a partire dalla sua posizione tra due dati adiacenti;
→ approssimazione quando può essere calcolato dalla intersezione con una funzione che approssima i dati e ne fornisce una appropriata descrizione;
→ estrapolazione quando, nell'uno e nell'altro caso, si assume che possa essere calcolato anche al di fuori dell'intervallo dei dati osservati.
L'approssimazione è ampiamente utilizzata in statistica, come ad esempio nel caso del metodo dei minimi quadrati, che consente di calcolare la funzione (retta o polinomio) che, sotto una serie di ipotesi [1], "meglio" approssima i dati. In ogni caso la x della quale si cerca la y corrispondente deve cadere nell'ambito (range) dei valori osservati perché il calcolo mediante la funzione approssimante possa essere ritenuto affidabile.
L'estrapolazione cioè l'estensione delle conclusioni al di la dei valori osservati è un'operazione da proscrivere, a meno che si disponga di un modello ben consolidato. Così ad esempio le leggi della meccanica celeste applicate a una sequenza di posizioni recenti di un asteroide possono consentire una estrapolazione della sua posizione in un tempo futuro, ma i casi di leggi deterministiche di questo genere sono limitati e collegati a campi specifici molto particolari.
Qui vediamo il caso più semplice, la interpolazione lineare, che assume che i due punti adiacenti alla x della quale si cerca la y corrispondente possano essere collegati da un segmento di retta. Nel caso di una curva, più i due punti adiacenti sono ravvicinati, più corto è il segmento di retta, più accurata è l'interpolazione.
Non sono richiesti pacchetti aggiuntivi, in quanto tutte le funzioni che impieghiamo sono incluse nell'installazione base di R. Ora copiate e incollate nella Console di R questa prima parte dello script e premete ↵ Invio.
# INTERPOLAZIONE LINEARE
#
x <- c(1.21, 1.32, 1.42, 1.53, 1.64, 1.75, 1.85, 1.96, 2.07, 2.18, 2.28, 2.39, 2.50, 2.61, 2.72, 2.82, 2.93, 3.04, 3.15, 3.25, 3.36, 3.47, 3.58, 3.68, 3.79) # valori in ascisse
y <- c(46.86, 47.08, 47.26, 47.42, 47.48, 47.46, 47.37, 47.22, 46.92, 46.61, 46.29, 45.98, 45.64, 45.29, 44.95, 44.64, 44.38, 44.15, 43.98, 43.92, 43.90, 43.93, 43.97, 44.09, 44.26) # valori in ordinate
#
plot(x, y, type="l") # traccia il grafico della funzione
#
Le prime due righe riportano le coppie di coordinate x,y dei dati osservati. Questo è il grafico risultante, tracciato nella terza riga con la funzione plot() che impiega per tutti gli argomenti i valori di default, specificando solamente che i punti devono essere collegati con una linea ("l") [2].

Ora supponiamo di avere per la x i valori 1.3, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0, 3.2, 3.4, 3.6, 3.7 e di volere calcolare mediante interpolazione lineare i valori della y corrispondenti.
Per farlo copiate e incollate nella Console di R queste due altre righe di codice e premete ↵ Invio.
#
interp <- approx(x, y, xout=c(1.3, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0, 3.2, 3.4, 3.6, 3.7), ties="ordered") # interpola una serie di valori specificati
#
#
round(cbind(interp$x, interp$y), digits=2) # mostra i risultati dell'interpolazione
#
L'interpolazione viene effettuata con la funzione approx() impiegando come argomenti:
→ le ascisse x dei punti che descrivono la funzione;
→ le ordinate y dei punti che descrivono la funzione;
→ le ascisse xout dei punti da interpolare;
→ l'indicazione "ordered" che indica che i dati di partenza sono già ordinati.
I risultati dell'approssimazione sono salvati nell'oggetto interp dal quale sono tratti i valori delle ascisse inseriti (interp$x) e i valori delle ordinate calcolati per ciascuno di essi (interp$y). Questi valori sono combinati in una tabella con la funzione cbind(), sono arrotondati con la funzione round() a due decimali (digits=2) e mostrati come segue:
> round(cbind(interp$x, interp$y), digits=2) # mostra i risultati dell'interpolazione
[,1] [,2]
[1,] 1.3 47.04
[2,] 1.4 47.22
[3,] 1.6 47.46
[4,] 1.8 47.42
[5,] 2.0 47.11
[6,] 2.2 46.55
[7,] 2.4 45.95
[8,] 2.6 45.32
[9,] 2.8 44.70
[10,] 3.0 44.23
[11,] 3.2 43.95
[12,] 3.4 43.91
[13,] 3.6 43.99
[14,] 3.7 44.12
Con questa riga di codice potete, per controllo, sovrapporre alla curva originaria i punti interpolati.
#
points(interp$x, interp$y, pch=3, col="red") # riporta sul grafico i punti interpolati
#
#
Come si vede i punti interpolati cadono tutti sulla curva e indicano una adeguata approssimazione.

Per interpolare un singolo valore e riportarlo sul grafico il codice da impiegare risulta ovviamente più conciso come in questo esempio.
#
val <- approx(x, y, xout=1.7) # interpola un singolo valore
#
points(val, pch=4, col="blue") # riporta sul grafico il punto interpolato
#
Per visualizzare il risultato numerico di questa ulteriore interpolazione è sufficiente nella Console di R digitare
val
che mostra il contenuto dell'oggetto, rappresentato dal valore della x inserita e da quello della y risultante:
> val
$x
[1] 1.7
$y
[1] 47.46909
----------
[1] Vedere il post La regressione lineare: assunti e modelli.
[2] Digitare help(plot) nella Console di R per la documentazione della funzione.