Per
ridurre la componente di incertezza nelle nostre decisioni, oltre che
utilizzare metodi di ragionamento “razionali”, è necessario
acquisire dati e informazioni “corretti”. Oggi si sente spesso
dire che ci si deve basare sull’evidenza. E i numeri sono per
definizione portatori di “evidenza”.
Ma
cosa è l’evidenza? Vediamo un esempio di evidenza statistica
impiegando variabili rilevate negli anni dal 1998 al 2002
dall’Istituto Nazionale di Statistica e dall'Istituto Superiore di
Sanità.
La
prima variabile è Procedimenti civili di primo grado pendenti a
fine anno, e la porremo sull'asse delle ascisse.
I valori sono tratti da “ISTAT,
Annuario statistico italiano 2004, pag. 136. Tavola 6.1 - Movimento
dei procedimenti civili per grado di giudizio e ufficio giudiziario -
Anni 1998-2002”
[1].
La
seconda variabile è Casi [di AIDS] diagnosticati, e la porremo sull'asse delle ordinate.
I valori sono tratti da “Notiziario dell’Istituto Superiore di Sanità,
Supplemento 1-2007, Aggiornamento dei casi di AIDS notificati in
Italia e delle nuove diagnosi di infezione da HIV, pag. 4. Tabella 1
- Distribuzione annuale dei casi di AIDS, dei casi corretti per
ritardo di notifica, dei decessi e del tasso di letalità”. [2]
I
valori riportati in questa tabella
Anno
|
Procedimenti
civili ... pendenti a fine anno (x)
|
Casi
[di AIDS] diagnosticati (y)
|
1998
|
10376
|
2441
|
1999
|
9159
|
2135
|
2000
|
8290
|
1948
|
2001
|
7924
|
1812
|
2002
|
6872
|
1756
|
sono analizzati con uno script con il quale sono calcolati il
coefficiente di correlazione r e l'equazione della retta di regressione (prima di eseguire lo script è necessario scaricare e installare il pacchetto Hmisc). Copiate questa prima parte dello script e incollatela nella Console di R e premete ↵ Invio:
#
r di Pearson ed equazione della retta y = a + b · x
#
x
<- c(10376,9159,8290,7924,6872) # valori in ascisse
y
<- c(2441,2135,1948,1812,1756) # valori in ordinate
mydata
<- data.frame(x,y) # per la funzione cor()
mymatrix
<- as.matrix(mydata) # per la funzione rcorr()
#
coefficients(lm(y
~ x)) # intercetta (a) e coefficiente angolare (b)
#
cor(mydata,
method="pearson") # coefficiente di correlazione
r
library(Hmisc)
# carica il pacchetto
rcorr(mymatrix,
type="pearson") # significatività di r
#
Questi
sono i risultati:
> coefficients(lm(y ~ x)) # intercetta (a) e coefficiente angolare (b)
(Intercept) x
270.6801141 0.2050304
> #
> cor(mydata, method="pearson") # coefficiente di correlazione r
x y
x 1.0000000 0.9748914
y 0.9748914 1.0000000
> library(Hmisc) # carica il pacchetto
Carico il pacchetto richiesto: lattice
Carico il pacchetto richiesto: survival
Carico il pacchetto richiesto: Formula
Carico il pacchetto richiesto: ggplot2
Attaching package: ‘Hmisc’
The following objects are masked from ‘package:base’:
format.pval, units
> rcorr(mymatrix, type="pearson") # significatività di r
x y
x 1.00 0.97
y 0.97 1.00
n= 5
P
x y
x 0.0048
y 0.0048
L'equazione
della retta di regressione è
y =
270.6801141
+ 0.2050304 · x
e il coefficiente di correlazione
r è uguale a 0.9748914.
La probabilità di osservare per caso questo valore è
p =
0.0048 cioè
è pari allo 0.48%. Anche se assumiamo un livello di significatività
dell'1%, molto più prudente del classico 5%, possiamo concludere che
tra le due variabili esiste, statisticamente parlando, una
correlazione significativa.
Le
fonti sono documentate e autorevoli. Ed esiste una "evidenza"
suffragata dai numeri che le due variabili variano congiuntamente.
Tuttavia l’evidenza dei numeri è in contrasto con la
ragionevolezza: perché non abbiamo un’ipotesi
plausibile in grado di spiegare come all’aumentare dell’efficienza
nell’amministrazione della giustizia civile la gente si ammali meno
di AIDS. I due fatti sono dal punto di vista causale "evidentemente" scollegati, anche se dal punto di vista statistico
"evidentemente" correlati.
Possiamo
anche arricchire l'analisi statistica tracciando il grafico, copiate questa seconda parte dello script e incollatela nella Console di R e premete ↵ Invio:
#
windows()
# apre una nuova finestra
plot(x,
y, xlim = c(6000,11000), ylim = c(1500,2500), xlab="Procedimenti
civili ... prendenti a fine anno", ylab="Casi [di AIDS] ...
diagnosticati", main="Regressione x variabile
indipendente") # grafico dei dati
abline(coefficients(lm(y
~ x)), col="lightblue") # retta di regressione x
variabile indipendente
#
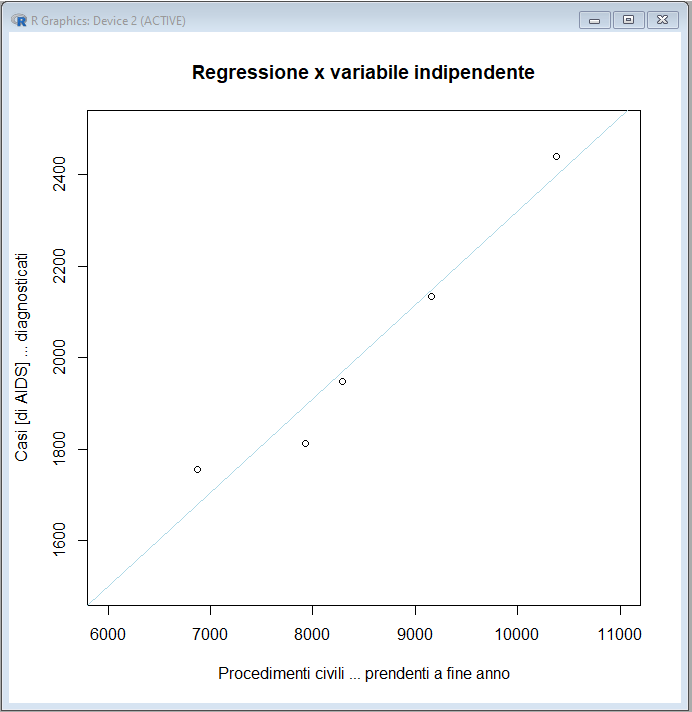
Immagino che chi si occupa di statistica e/o dati scientifici possa aver avuto o abbia prima o poi l'occasione di vedere un grafico di questo genere associato a una affermazione di "correlazione lineare statisticamente significativa". Cosa che si può fare solamente se abbiamo a monte un modello che illustra e spiega la connessione tra le due variabili.
Ma il percorso inverso, con l'assunzione
implicita di un rapporto di causa-effetto in seguito ad un
coefficiente di correlazione significativo, è un errore da evitare. Richiami all'attenzione
li potete trovare in Marubini [3] e in Campbell [4], e a
tutt'oggi esiste almeno un sito web interamente dedicato ad
illustrare esempi grotteschi di correlazioni statisticamente significative ma causalmente, logicamente e razionalmente insensate [5].
Infine a chi fosse interessato ad ulteriori approfondimenti e a un approccio razionale al tema dell'inferenza causale in statistica, consiglio un lavoro di Judea Pearl [6].
----------
[1]
ISTAT, Annuario statistico italiano 2004.
https://ebiblio.istat.it/digibib/Annuario%20Statistico%20Italiano/RAV0040597ASI2004.pdf
[2]
Notiziario dell’Istituto Superiore di Sanità, Supplemento
1-2007.
https://www.epicentro.iss.it/aids/pdf/coa-2007.pdf
[3]
Bossi A, Cortinovis I, Duca PG, Marubini E. Introduzione alla
statistica medica. La Nuova Italia Scientifica, Roma, 1994, ISBN
88-430-0284-8, pp. 89-90.
[4]
“Correlation is not causation”. In: Campbell MJ, Machin D.
Medical Statistics. A Commonsense Approach. John Wiley &
Sons, New York, 1993, ISBN 0-471-93764-9, p. 103.
[5]
Spurious
correlations.
https://tylervigen.com/spurious-correlations
[6] Judea Pearl. "Causal inference in statistics: An overview." Statist. Surv. 3 96 - 146, 2009.
https://doi.org/10.1214/09-SS057
Nessun commento:
Posta un commento