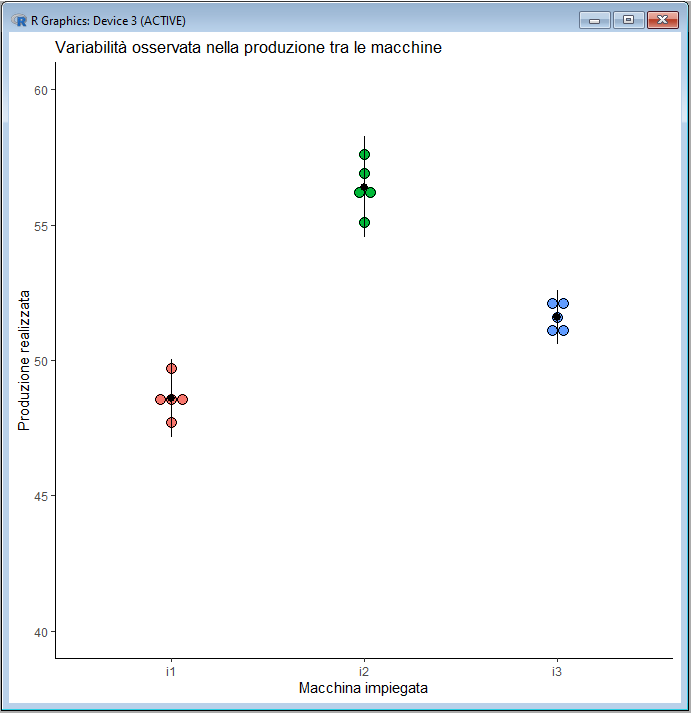
Il complesso di tecniche statistiche note come analisi della varianza (ANOVA) è stato introdotto con l'analisi della varianza a un fattore con la quale avevamo analizzato i dati di produzione di tre macchine, azionate da operatori non meglio specificati, con la domanda: le differenze tra le medie di produzione delle tre macchine possono essere attribuite al caso? Se così non fosse, dovremmo pensare che esiste qualcosa in grado di influenzare la produzione media delle macchine.
Il disegno sperimentale adottato aveva previsto di raccogliere i dati in modo tale che la variabilità osservata, misurata dalla differenza tra le medie di produzione delle i macchine, risultava essere quella determinata dal fattore macchina+operatore. Questi erano i dati riportati da Wonnacott [1] che abbiamo impiegato

e questo è il grafico che li rappresentava (in nero la media ± 2 deviazioni standard) e che mostra come medie risultassero tutte e tre significativamente diverse l'una dall'altra.

Ci proponiamo ora di fare un passo ulteriore: decomporre la variabilità osservata in variabilità dovuta al fattore macchina e variabilità dovuta al fattore operatore. Per questo impieghiamo di nuovo dati illustrati da Wonnacott [2], ma raccolti diversamente, che riportano nelle righe la produzione delle macchine e nelle colonne gli operatori che le azionano. Da notare che le medie [della produzione] delle macchine sono identiche alle precedenti, ma i dati hanno una distribuzione di valori più ampia, un fatto molto importante e che si ripercuote sulle conclusioni che dai dati possiamo trarre.

Il disegno sperimentale adottato ci consente di confrontare tra loro sia le medie delle i macchine (ultima colonna), sia le medie dei j diversi operatori (ultima riga) e analizzare le differenze tra le medie rispondendo separatamente a due domande:
→ le differenze tra le medie delle macchine possono essere attribuite al caso?
→ le differenze tra le medie degli operatori possono essere attribuite al caso?
Se così non fosse (cioè se le differenze non possono essere attribuite al caso) dovremmo pensare che esiste qualcosa in grado di influenzare la produzione media delle macchine (ad esempio differenze strutturali, inadeguata manutenzione o altro) e/o qualcosa in grado di influenzare la produzione media degli operatori (ad esempio formazione dell'operatore, fenomeni di fatica o altro).
I dati riportati in forma di tabella da Wonnacott per essere analizzati con R devono essere organizzati in un file di testo, sotto forma di righe (record) contenenti ciascuna tre variabili (campi), una prima variabile qualitativa (fattore) che indica la macchina, una seconda variabile qualitativa (fattore) che indica l'operatore e una variabile numerica che indica la produzione della combinazione macchina/operatore, e assumono quindi la forma seguente:
macchina;operatore;produzione
i1;j1;56.7
i1;j2;45.7
i1;j3;48.3
i1;j4;54.6
i1;j5;37.7
i2;j1;64.5
i2;j2;53.4
i2;j3;54.3
i2;j4;57.5
i2;j5;52.3
i3;j1;56.7
i3;j2;50.6
i3;j3;49.5
i3;j4;56.5
i3;j5;44.7
i1;j1;56.7
i1;j2;45.7
i1;j3;48.3
i1;j4;54.6
i1;j5;37.7
i2;j1;64.5
i2;j2;53.4
i2;j3;54.3
i2;j4;57.5
i2;j5;52.3
i3;j1;56.7
i3;j2;50.6
i3;j3;49.5
i3;j4;56.5
i3;j5;44.7
Copiate le sedici righe riportate qui sopra aggiungendo un ↵ Invio al termine dell'ultima riga e salvatele in C:\Rdati\ in un file di testo denominato anova2.csv (attenzione all'estensione .csv al momento del salvataggio del file).
In alternativa andate alla pagina Dati nella quale trovate diverse opzioni per scaricare i file di dati, quindi copiate il file anova2.csv nella cartella C:\Rdati\
Scaricate dal CRAN e installate il pacchetto ggplot2, con il quale realizzeremo una rappresentazione grafica dei dati integrativa all'analisi statistica.
Infine copiate e incollate nella Console di R questo script e premete ↵ Invio:
# ANOVA analisi della varianza a due fattori
#
mydata <- read.table("c:/Rdati/anova2.csv", header=TRUE, sep=";", dec=".") # importa i dati [1]
#
anova2 <- aov(produzione~macchina+operatore, data=mydata) # calcola la variabilità tra macchine e tra operatori
summary(anova2) # mostra i risultati
#
pairwise.t.test(mydata$produzione, mydata$macchina, p.adjust.method = "bonferroni") # confronto tra le (produzioni) medie delle macchine impiegando il test t con la correzione di bonferroni per confronti multipli
pairwise.t.test(mydata$produzione, mydata$operatore, p.adjust.method = "bonferroni") # confronto tra le (produzioni) medie degli operatori impiegando il test t con la correzione di bonferroni per confronti multipli [2]
#
Lo script è suddiviso in tre blocchi di codice. Nel primo blocco sono importati i dati con la funzione read.table().
Nel secondo viene eseguita l'analisi della varianza a un fattore mediante la funzione aov() (seconda riga) e sono riepilogati (terza riga) i risultati con la funzione summary():
Df Sum Sq Mean Sq F value Pr(>F)
macchina 2 154.8 77.40 13.10 0.002997 **
operatore 4 381.7 95.43 16.15 0.000673 ***
Residuals 8 47.3 5.91
---
Signif. Codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
La varianza (Mean Sq) è calcolata dividendo la somma degli scarti quadratici (Sum Sq) per i gradi di libertà (Df). Il valore F (F value) viene calcolato separatamente per la macchina e per l'operatore, dividendo la varianza dovuta alle macchine (77.40) per la varianza residua (5.91) ovvero dividendo la varianza dovuta agli operatori (95.43) per la varianza residua (5.91) .
La probabilità (Pr(>F)) è la probabilità di osservare per caso il valore F e consente di rispondere alla domanda: le differenze tra le medie di produzione possono essere attribuite al caso? Per le medie di produzione delle macchine abbiamo un valore Pr(>F)= 0.002997 e per le medie di produzione degli operatori abbiamo un valore Pr(>F)= 0.000673. Poiché entrambi sono inferiori al valore 0.05 assunto in genere come valore soglia, concludiamo che le differenze osservate non sono attribuibili al caso o, se preferite, che sono significative: quindi esiste qualcosa in grado di influenzare la produzione a livello delle macchine e/o a livello degli operatori.
Il terzo blocco di codice consiste in due righe di codice, una per analizzare i dati delle macchine, e una analizzare i dati degli operatori. Abbiamo già visto che l'analisi della varianza a un fattore è una generalizzazione del test t di Student per dati non appaiati, ed è equivalente al test t quando i gruppi sono due [4]. Tuttavia esistono delle correzioni del test t che consentono di impiegarlo anche nel caso del confronto di più di due gruppi [5]. Queste correzioni controbilanciano l'aumento della probabilità, derivante dall'esecuzione di confronti multipli, di considerare la differenza tra le medie di due campioni come significativa quando invece non è significativa, ed è proprio una di queste, la correzione di Bonferroni (p.adjust.method = "bonferroni"), che viene qui applicata ai dati mediante la funzione pairwise.t.test(). Mentre l'ANOVA è un test globale, che ci dice che tra le medie esiste una qualche differenza, ma non ci consente di individuare la/e media/e responsabile/i di tale differenza, il test t viene effettuato per tutti i confronti possibili tra medie.
Il test t effettuato per tutti i confronti possibili tra macchine indica differenze sempre non significative - essendo sempre superiori a 0.05 le probabilità che le differenze tra medie qui osservate siano dovute al caso:
> pairwise.t.test(mydata$produzione, mydata$macchina, p.adjust.method = "bonferroni") # confronto tra le (produzioni) medie delle macchine impiegando la correzione di bonferroni per confronti multipli
Pairwise comparisons using t tests with pooled SD
data: mydata$produzione and mydata$macchina
i1 i2
i2 0.18 -
i3 1.00 0.69
P value adjustment method: bonferroni
Il test t effettuato per tutti i confronti possibili tra operatori ci indica che la significatività dall'ANOVA è dovuta ad un'unica differenza tra tutti i confronti effettuati: j1 risulta diverso da j5 con un valore p=0.029, di poco inferiore al valore soglia 0.05 comunemente adottato:
> pairwise.t.test(mydata$produzione, mydata$operatore, p.adjust.method = "bonferroni") # confronto tra le (produzioni) medie degli operatori impiegando la correzione di bonferroni per confronti multipli
Pairwise comparisons using t tests with pooled SD
data: mydata$produzione and mydata$operatore
j1 j2 j3 j4
j2 0.283 - - -
j3 0.411 1.000 - -
j4 1.000 1.000 1.000 -
j5 0.029 1.000 1.000 0.117
P value adjustment method: bonferroni
Quindi mentre l'ANOVA indica la presenza nei dati di una qualche differenza significativa, il test t con la correzione di Bonferroni consente di rilevare dove questa si trova in quanto:
→ nel confronto tra le medie delle macchine indica differenze sempre non significative;
→ nel confronto tra le medie degli operatori indica che la differenza è imputabile ad un unico caso, quello degli operatori j1 e j5.
Se oltre alla libreria ggplot2 installate la libreria gridExtra potete realizzare un grafico a punti [6] che visualizza i dati della variabilità tra le macchine e un grafico a punti che visualizza i dati delle variabilità tra gli operatori, e combinarli in un'unica figura.
Copiate e incollate nella Console di R questo script e premete ↵ Invio:
#
library(ggplot2) # carica il pacchetto per la grafica
library(gridExtra) # carica il pacchetto per combinare i grafici
#
plot1 <- ggplot(mydata, aes(x=macchina, y=produzione, fill=macchina)) + geom_dotplot(binaxis='y', stackdir='center', stackratio=1, dotsize=1, binwidth=0.4, show.legend=FALSE) + coord_cartesian(ylim=c(40, 70)) + labs(title="Variabilità tra le macchine", x="Macchina impiegata", y="Produzione realizzata") + theme_classic() # dotplot della produzione per macchina
#
plot2 <- ggplot(mydata, aes(x=operatore, y=produzione, fill=operatore)) + geom_dotplot(binaxis='y', stackdir='center', stackratio=1, dotsize=1, binwidth=0.4, show.legend=FALSE) + coord_cartesian(ylim=c(40, 70)) + labs(title="Variabilità tra gli operatori", x="Operatore", y="Produzione realizzata") + theme_classic() # dotplot della produzione per operatore
grid.arrange(plot1, plot2, nrow = 1) # i due dotplot sono mostrati affiancati orizzontalmente
#

Se l'ANOVA consente di effettuare un confronto tra medie, a questo punto sembra logico sovrapporre ai dati raccolti la loro media e la loro deviazione standard.
Copiate e incollate nella Console di R queste quattro righe di codice che aprono una nuova finestra grafica nella quale viene rappresentato il grafico che sovrappone ai punti la media con l'intervallo corrispondente a due deviazioni standard:
#
windows() # apre e inizializza una nuova finestra grafica
#
plot1 <- ggplot(mydata, aes(x=macchina, y=produzione, fill=macchina)) + geom_dotplot(binaxis='y', stackdir='center', stackratio=1, dotsize=1, binwidth=0.4, show.legend=FALSE) + coord_cartesian(ylim=c(40, 70)) + labs(title="Variabilità tra le macchine", x="Macchina impiegata", y="Produzione realizzata") + theme_classic() + stat_summary(fun.data = mean_sdl, fun.args=list(mult=2), geom="pointrange", color="black", show.legend = FALSE) # dotplot della produzione per macchina +/- 2 deviazioni standard
#
plot2 <- ggplot(mydata, aes(x=operatore, y=produzione, fill=operatore)) + geom_dotplot(binaxis='y', stackdir='center', stackratio=1, dotsize=1, binwidth=0.4, show.legend=FALSE) + coord_cartesian(ylim=c(40, 70)) + labs(title="Variabilità tra gli operatori", x="Operatore", y="Produzione realizzata") + theme_classic() + stat_summary(fun.data = mean_sdl, fun.args = list(mult=2), geom="pointrange", color="black", show.legend=FALSE) # dotplot della produzione per macchina +/- 2 deviazioni standard
#grid.arrange(plot1, plot2, nrow = 1) # i due dotplot sono mostrati affiancati orizzontalmente
#
Da notare che nella funzione stat_summary() l'argomento mult=2 che specifica di rappresentare attorno alla media l'intervallo uguale a 2 deviazioni standard può essere modificato.
La rappresentazione grafica dei dati ci viene nuovamente in aiuto nell'interpretazione dei risultati. Come si vede in questo caso i dati sono molto dispersi, e gli intervalli media ± 2 deviazioni standard sono ampiamente sovrapposti: e questo corrobora la non significatività delle differenze tra le medie. Da notare la notevole differenza rispetto ai dati dell'ANOVA a un fattore riportati nella prima figura in alto. La maggior differenza rilevata graficamente è quella tra operatore j1 e operatore j5 ed è in linea con la debole (appena inferiore a 0.05) significatività statistica (p=0.029) di tale differenza.

La conclusione? Impiegando i dati tratti da un testo di statistica abbiamo sviluppato due esempi di analisi della varianza, a un fattore [7] e a due fattori, dai quali possiamo ricavare alcune considerazioni interessanti:
→ l'analisi della varianza (ANOVA), a dispetto del nome, è un insieme di tecniche per effettuare confronti multipli tra medie;
→ perché l'ANOVA fornisca risultati affidabili è necessario verificare in via preliminare che i dati siano distribuiti in modo gaussiano e con varianze omogenee, eseguendo i test opportuni;
→ l'ANOVA fornisce come risultato un rapporto tra varianze (il test F), che è un test globale che ci dice che tra le medie esiste una qualche differenza, ma non specifica la/e media/e responsabile/i di tale differenza;
→ nel caso limite in cui il confronto tra medie è limitato a due campioni l'ANOVA equivale al test t di Student per dati non appaiati (campioni indipendenti);
→ i confronti multipli tra medie possono essere effettuati anche impiegando test alternativi come il test t con opportune correzioni, ad esempio con la correzione di Bonferroni, con il vantaggio, in questo caso, che la significatività viene valutata separatamente per ciascuna coppia di medie poste a confronto;
→ il valore soglia p=0.05 non è un dogma, e qualora si ritenga opportuno essere più prudenti (conservativi) nel giudicare la significatività di un test statistico si può adottare un valore soglia inferiore come per esempio p=0.01;
→ quando i dati sono poco dispersi e l'intervallo media ± 2 deviazioni standard non si sovrappone i risultati di ANOVA e test t (con le opportune correzioni) sono uguali in quanto l'informazione fornita dai dati è elevata, lascia poco adito a dubbi [sulla significatività delle differenze tra le medie] e la diversità degli assunti alla base delle tecniche statistiche impiegate non porta a conclusioni diverse;
→ quando i dati sono molto dispersi e l'intervallo media ± 2 deviazioni standard è ampiamente sovrapposto (vedere la seconda e la terza immagine riportate qui sopra), i risultati di ANOVA e test t (con le opportune correzioni) possono differire in quanto l'informazione fornita dai dati è scarsa, lascia adito a molti dubbi [sulla significatività delle differenze tra le medie] e la diversità degli assunti alla base delle tecniche statistiche impiegate può portare a conclusioni diverse;
→ la rappresentazione grafica dei dati rappresenta come sempre una importante integrazione ai test statistici.
In sintesi anche i risultati dell'ANOVA, come del resto tutti i risultati dell'analisi statistica, non devono essere interpretati in modo schematico e rigido, ma devono essere interpretati:
→ verificando che i dati analizzati rispettino gli assunti di normalità e omogeneità delle varianze previsti dall'ANOVA;
→ integrando i risultati dell'ANOVA con quelli di test alternativi per il confronto tra medie;
→ valutando criticamente le eventuali discrepanze tra i risultati dell'ANOVA e dei test alternativi;
→ adottando al bisogno requisiti di significatività più stringenti del tradizionale p=0.05;
→ integrando i risultati dell'ANOVA e dei test alternativi con l'esplorazione grafica dei dati;
→ traendo le conclusioni sulla base di una valutazione globale dei risultati ottenuti.
Il che ci ricorda che tutto sommato in statistica il rigore scientifico dei modelli matematici e dei numeri dovrebbe sempre essere integrato con il buonsenso, al quale può contribuire in modo importante una adeguata rappresentazione grafica.
----------
[1] Wonnacott TH, Wonnacott RJ. Introduzione alla statistica. Franco Angeli Editore, Milano, 1980, ISBN 88-204-0323-4, Tabella 10-1, p. 238.
[2] Wonnacott TH, Wonnacott RJ. Introduzione alla statistica. Franco Angeli Editore, Milano, 1980, ISBN 88-204-0323-4, Tabella 10-9, p. 255.
[3] L'analisi della varianza è basata su due ipotesi: (i) che i dati siano distribuiti in modo gaussiano e (ii) che la varianza sia la stessa nei diversi gruppi confrontati.
[4] Vedere il post Test parametrici e non parametrici per due campioni indipendenti.
[5] Vedere il post Test parametrici e non parametrici per più campioni indipendenti.
[6] Per i dettagli delle funzioni e degli argomenti impiegati per questa rappresentazione grafica si rimanda al post Grafici a punti (dotplot) mentre nel post Grafici a violino (violin plot) trovate anche come sovrapporre ai punti un grafico a violino o un grafico a scatola con i baffi (boxplot).