Abbiamo una
distribuzione bimodale quando, all'interno della stessa variabile, coesistono due sottoinsiemi differenti, con
differente moda (e media).
In
effetti è noto che la concentrazione degli eritrociti (globuli rossi) nel sangue
nella donna è mediamente inferiore a quella presente nell'uomo.
Impiegando la concentrazione degli eritrociti nel sangue rilevata in 202 atleti australiani riportata nella colonna/variabile rcc della tabella ais inclusa nel pacchetto DAAG, verifichiamo la loro distribuzione impiegando uno script
che genera due kernel density plot separati - uno per il sesso/fattore
m e uno per il sesso/fattore f - e vediamo se si sovrappongono. Accertatevi di avere installato il pacchetto o in alternativa procedete come indicato in [1].
Lo
script richiede inoltre il pacchetto aggiuntivo sm che deve essere anch'esso preventivamente scaricato e installato dal CRAN.
#
KERNEL DENSITY PLOT SOVRAPPOSTI separati per sesso
#
library(DAAG)
# carica il pacchetto DAAG che include il set di dati ais
str(ais)
# mostra la struttura di ais
#
library(sm)
# carica il pacchetto
attach(ais)
# funzione per impiegare direttamente i nomi delle variabili di ais
#
# al termine fare click con il tasto sinistro del mouse nel punto in cui si desidera posizionare la legenda
#
windows() # apre una nuova finestra
# al termine fare click con il tasto sinistro del mouse nel punto in cui si desidera posizionare la legenda
#
windows() # apre una nuova finestra
sm.density.compare(rcc,
sex, xlab="Eritrociti in 10^12/L", ylab="Stima kernel
di densità") # traccia kernel density plot separati
per sesso
title(main="Concentrazione degli eritrociti per sesso") # aggiunge il titolo
sesso <- factor(sex, levels= c("f","m"), labels = c("Donna", "Uomo")) # identifica i casi per sesso
colfill<-c(2:(2+length(levels(sesso)))) # predispone i colori
legend(locator(1), levels(sesso), fill=colfill) # posiziona la legenda
#
title(main="Concentrazione degli eritrociti per sesso") # aggiunge il titolo
sesso <- factor(sex, levels= c("f","m"), labels = c("Donna", "Uomo")) # identifica i casi per sesso
colfill<-c(2:(2+length(levels(sesso)))) # predispone i colori
legend(locator(1), levels(sesso), fill=colfill) # posiziona la legenda
#
Dopo
avere caricato il pacchetto DAAG con il set di dati ais, viene
mostrata la struttura dei dati:
> library(DAAG) # carica il pacchetto DAAG incluso il set di dati ais
Carico il pacchetto richiesto: lattice
> str(ais) # mostra la struttura di ais
'data.frame': 202 obs. of 13 variables:
$ rcc : num 3.96 4.41 4.14 4.11 4.45 4.1 4.31 4.42 4.3 4.51 ...
$ wcc : num 7.5 8.3 5 5.3 6.8 4.4 5.3 5.7 8.9 4.4 ...
$ hc : num 37.5 38.2 36.4 37.3 41.5 37.4 39.6 39.9 41.1 41.6 ...
$ hg : num 12.3 12.7 11.6 12.6 14 12.5 12.8 13.2 13.5 12.7 ...
$ ferr : num 60 68 21 69 29 42 73 44 41 44 ...
$ bmi : num 20.6 20.7 21.9 21.9 19 ...
$ ssf : num 109.1 102.8 104.6 126.4 80.3 ...
$ pcBfat: num 19.8 21.3 19.9 23.7 17.6 ...
$ lbm : num 63.3 58.5 55.4 57.2 53.2 ...
$ ht : num 196 190 178 185 185 ...
$ wt : num 78.9 74.4 69.1 74.9 64.6 63.7 75.2 62.3 66.5 62.9 ...
$ sex : Factor w/ 2 levels "f","m": 1 1 1 1 1 1 1 1 1 1 ...
$ sport : Factor w/ 10 levels "B_Ball","Field",..: 1 1 1 1 1 1 1 1 1 1 …
La
variabile
sex e
la variabile
sport,
le due ultime elencate, sono i fattori che possono essere impiegati
per la classificazione dei casi. La prima prevede due livelli di classificazione dei casi (m,
f),
la seconda ne prevede dieci (B_Ball,
Field,
Gym,
Netball,
Row,
Swim,
T_400m,
T_Sprnt,
Tennis,
W_Polo).
Nello
script per tracciare i kernel density plot separati per i due sessi
viene impiegata la funzione sm.density.compare()
del pacchetto sm, che prevede molto semplicemente come primo
argomento la variabile (rcc) da
analizzare e come secondo argomento il fattore (sex)
da impiegare per la classificazione dei casi.
Il
codice fa una cosa piuttosto interessante: dopo avere tracciato due
kernel density plot indipendenti e sovrapposti per i soggetti di
sesso maschile (m)
e di sesso femminile (f)
rimane in attesa. A questo punto, posizionate
il mouse dove volete che compaia la legenda [2] e fate click con il tasto sinistro del mouse per farla comparire (e
terminare lo script).
Il
codice riportato non consente di spostare la legenda. Se non si è
soddisfatti della sua posizione, è necessario rieseguire l’intero
script e fare nuovamente click con il tasto sinistro del mouse nel
punto in cui si vuole posizionare la legenda.
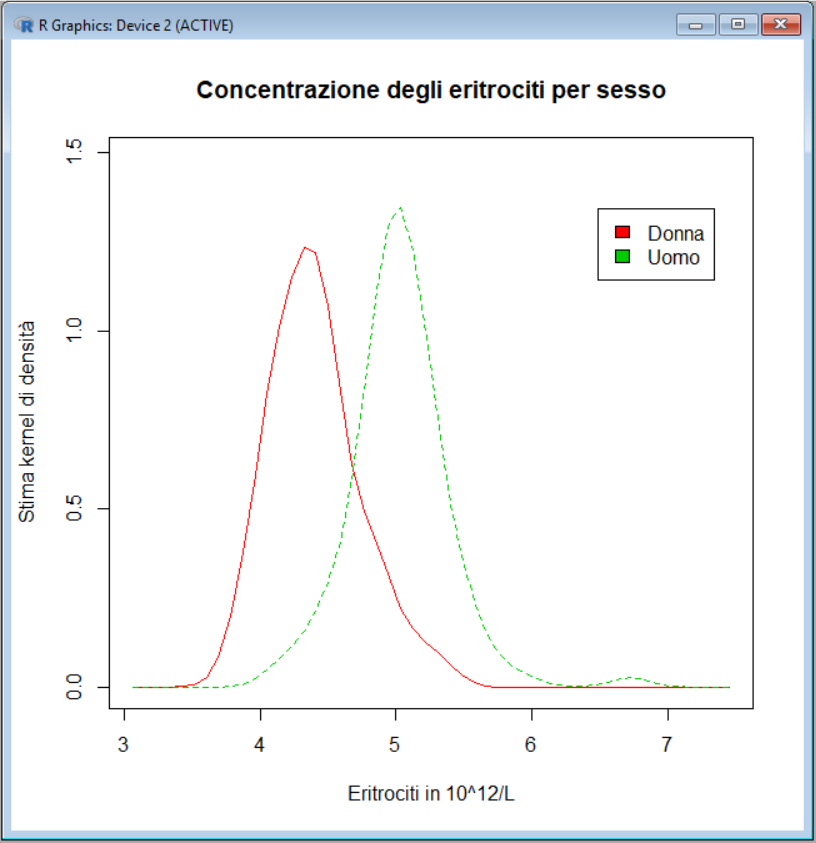
Come
risulta evidente dal grafico i kernel density plot separati per sesso
mostrano per la concentrazione degli eritrociti nel siero degli atleti australiani la
presenza di due sottopopolazioni, una dovuta alle donne, con valori mediamente inferiori, e una dovuta agli uomini, con valori mediamente superiori. Quando i dati sono rappresentati senza essere differenziati per sesso, queste due sottopopolazioni si sommano, determinando la distribuzione
bimodale degli eritrociti che si osserva negli istogrammi e nei kernel density plot [3].
Possiamo
effettuare un ulteriore approfondimento grafico sugli eritrociti
mediante kernel density plot separati per ciascuno degli sport.
Copiate
quest'altro script, incollatelo nella
Console di R e
premete ↵
Invio:
#
KERNEL DENSITY PLOT SOVRAPPOSTI separati per sport
#
library(DAAG)
# carica il pacchetto DAAG incluso il set di dati ais
str(ais)
# mostra la struttura di ais
#
library(sm)
# carica il pacchetto
attach(ais)
# funzione per impiegare direttamente i nomi delle variabili di ais
#
#
al termine fare click con il tasto sinistro del mouse nel punto in
cui si desidera posizionare la legenda
#
windows()
# apre una nuova finestra
mycol
<- c("green", "red", "purple",
"blue", "cyan", "grey50", "brown",
"tomato", "magenta", "gold") #
predispone i colori per ciascuno sport
sm.density.compare(rcc,
sport, col=mycol, xlab="Eritrociti in 10^12/L", ylab="Stima
kernel di densità") # traccia kernel density plot
separati per sport
title(main="Concentrazione degli eritrociti per sport") # aggiunge il titolo
sprt <- factor(sport, levels=c("B_Ball", "Field", "Gym", "Netball", "Row", "Swim", "T_400m", "T_Sprnt", "Tennis", "W_Polo"), labels=c("Basketball", "Field", "Gymnastics", "Netball", "Rowing", "Swimming", "Track 400m", "Track Sprint", "Tennis", "Water Polo")) # identifica i casi per sport
title(main="Concentrazione degli eritrociti per sport") # aggiunge il titolo
sprt <- factor(sport, levels=c("B_Ball", "Field", "Gym", "Netball", "Row", "Swim", "T_400m", "T_Sprnt", "Tennis", "W_Polo"), labels=c("Basketball", "Field", "Gymnastics", "Netball", "Rowing", "Swimming", "Track 400m", "Track Sprint", "Tennis", "Water Polo")) # identifica i casi per sport
legend(locator(1),
levels(sprt), fill=mycol) # posiziona la legenda
#
In questo caso i colori sono scelti e assegnati a ciascuno sport mediante il vettore mycol che viene poi impiegato sia nella funzione sm.density.compare() sia nella funzione legend().
Di nuovo posizionate il mouse dove volete che compaia la legenda, e fate click con il tasto sinistro del mouse per farla comparire (e terminare lo script).

Questo grafico fornisce una prova tangibile delle notevoli rappresentazioni grafiche che possono essere realizzate con R quando i dati in ingresso sono adeguatamente raccolti e organizzati.
Di nuovo posizionate il mouse dove volete che compaia la legenda, e fate click con il tasto sinistro del mouse per farla comparire (e terminare lo script).

Questo grafico fornisce una prova tangibile delle notevoli rappresentazioni grafiche che possono essere realizzate con R quando i dati in ingresso sono adeguatamente raccolti e organizzati.
----------
[1] Vedere il post Il set di dati ais. La concentrazione degli eritrociti viene espressa in 1012/L o in 106/µL, le due unità di misura impiegate nella pratica, che sono numericamente identiche. Nel post trovate anche come caricare i dati della tabella senza impiegare il pacchetto DAAG.
Nessun commento:
Posta un commento