La ricerca di una possibile correlazione, intesa come la tendenza di due grandezze a variare congiuntamente in modo statisticamente significativo, richiede – oltre alla necessità ineludibile di spiegare per quale ragione l'una dipenda dall'altra – un approccio integrato che include il calcolo del coefficiente di correlazione, la regressione lineare e l'esecuzione dei test di normalità. Lo vediamo ora con tre script da tenere a portata di mano per un impiego immediato al bisogno.
Gli script consentono per la parte statistica di calcolare:
→ il coefficiente di correlazione lineare r di Pearson (test parametrico)
→ il coefficiente di correlazione per ranghi ρ (rho) di Spearman (test non parametrico)
→ il coefficiente di correlazione τ (tau) di Kendall (test non parametrico)
Quale dei tre coefficienti impiegare per trarre dai propri dati le conclusioni in merito alla significatività della correlazione deve essere valutato di volta in volta alla luce delle seguenti considerazioni:
1) come suggerisce anche la sua denominazione completa e corretta, il coefficiente di correlazione lineare r di Pearson fornisce una misura accurata del grado di correlazione quando sono soddisfatti i seguenti due requisiti: (i) i dati hanno una distribuzione gaussiana [1] in quanto si tratta di un test parametrico; (ii) tra le due variabili a confronto esiste una relazione lineare;
2) i due coefficienti di correlazione non parametrici (ρ e τ) forniscono una misura della correlazione valida anche quando i dati non sono distribuiti in modo gaussiano e tra le due variabili a confronto non esiste una relazione lineare;
3) i test non parametrici sono più conservativi cioè tendono a fornire valori di p superiori (quindi valori di p meno significativi) rispetto al test parametrico; se si preferisce essere più prudenti nelle conclusioni, si possono applicare i test non parametrici anche quando i dati soddisfano i requisiti di gaussianità e di linearità che consentirebbero l'applicazione del test parametrico. Il coefficiente di correlazione τ di Kendall è il più conservativo.
Per eseguire gli script è necessario disporre dei pacchetti mblm e moments [2], se non li avete dovete scaricarli e installarli dal CRAN. Gli script prevedono tutti la stessa sequenza logica che include:
a) il calcolo dei tre coefficienti di correlazione per una immediata comparazione dei loro risultati;
b) il calcolo della significatività dei coefficienti di correlazione;
c) un grafico xy con la retta di regressione;
d) i test per la valutazione della normalità (gaussianità) dei dati.
Con il primo script viene calcolato il coefficiente di correlazione lineare r di Pearson (test parametrico) e viene rappresentata la regressione lineare parametrica. Copiate e incollate nella Console di R lo script e premete ↵ Invio:
# Coefficiente di correlazione lineare r di Pearson e regressione lineare parametrica
#
x <- c(18, 46, 89, 72, 96, 63, 23, 58, 36, 82, 88) # variabile in ascisse
y <- c(21, 41, 94, 64, 91, 71, 19, 66, 42, 89, 79) # variabile in ordinate
#
# coefficienti di correlazione
#
options(scipen=999) # predispone espressione dei numeri in formato fisso
cor.test(x, y, method="pearson") # r di Pearson
cor.test(x, y, method="spearman") # ρ (rho) di Spearman
cor.test(x, y, method="kendall") # τ (tau) di Kendall
#
# test di gaussianità
#
library(moments) # carica il pacchetto
agostino.test(x) # test di D'Agostino per il coefficiente di asimmetria di x
anscombe.test(x) # test di Anscombe-Glynn per il coefficiente di curtosi
#
agostino.test(y) # test di D'Agostino per il coefficiente di asimmetria di y
anscombe.test(y) # test di Anscombe-Glynn per il coefficiente di curtosi
#
shapiro.test(x) # test di Shapiro-Wilk
shapiro.test(y)
#
# grafico xy
#
plot(x, y, xlim = c(min(x), max(x)), ylim = c(min(y), max(y)), main="Regressione lineare (parametrica)")
#
# aggiunge al grafico la regressione lineare (parametrica) con r di Pearson
#
reglin <- lm(y~x) # calcola la regressione lineare
a <- reglin$coefficients[1] # intercetta a
b <- reglin$coefficients[2] # coefficiente angolare b
r <- cor(x, y, method="pearson") # coefficiente di correlazione r
#
lines(c(min(x), max(x)), c(a+b*min(x), a+b*max(x)), col="black", lty=2, lwd=1) # traccia la retta di regressione
#
legend(min(x), max(y), legend=c(paste("Intercetta a =", round(a, digits=0)), paste("Coefficiente angolare b =", round(b, digits=3)), paste("Equazione: y =", round(a, digits=0), ifelse(sign(b) == 1, "+", "-"), round(b, digits=3), "· x"), paste("r di Pearson =", round(r, digits=3)))) # aggiunge al grafico la legenda
#
options(scipen=0) # ripristina espressione dei numeri in formato esponenziale
#
Dopo avere definito nelle prime due righe di codice i dati da analizzare come x e come y, il che consente di sostituirli agevolmente con i propri, e dopo avere predisposto l'espressione dei numeri in formato fisso con options(scipen=999), mediante la funzione cor.test() sono subito calcolati i tre coefficienti di correlazione.
> cor.test(x, y, method="pearson") # r di Pearson
Pearson's product-moment correlation
data: x and y
t = 11.83, df = 9, p-value = 0.0000008695
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.8827108 0.9922369
sample estimates:
cor
0.9693169
> cor.test(x, y, method="spearman") # ρ (rho) di Spearman
Spearman's rank correlation rho
data: x and y
S = 14, p-value < 0.00000000000000022
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.9363636
> cor.test(x, y, method="kendall") # τ (tau) di Kendall
Kendall's rank correlation tau
data: x and y
T = 49, p-value = 0.0003334
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
0.7818182
I coefficienti r di Pearson (p = 0.0000008695), ρ (rho) di Spearman (p < 0.00000000000000022) e τ (tau) di Kendall (p = 0.0003334) sono sempre significativi. Quest'ultimo con suo il valore inferiore di p conferma di essere il più conservativo dei tre.
Il test di asimmetria
> agostino.test(x) # test di D'Agostino per il coefficiente di asimmetria
D'Agostino skewness test
data: x
skew = -0.30031, z = -0.55045, p-value = 0.582
alternative hypothesis: data have a skewness
e il test di curtosi
> anscombe.test(x) # test di Anscombe-Glynn per il coefficiente di curtosi
Anscombe-Glynn kurtosis test
data: x
kurt = 1.7415, z = -1.1572, p-value = 0.2472
alternative hypothesis: kurtosis is not equal to 3
confermano una distribuzione normale della variabile x.
Di nuovo il test di asimmetria
> agostino.test(y) # test di D'Agostino per il coefficiente di asimmetria
D'Agostino skewness test
data: y
skew = -0.38458, z = -0.70302, p-value = 0.482
alternative hypothesis: data have a skewness
e il test di curtosi
> anscombe.test(y) # test di Anscombe-Glynn per il coefficiente di curtosi
Anscombe-Glynn kurtosis test
data: y
kurt = 1.7976, z = -1.0283, p-value = 0.3038
alternative hypothesis: kurtosis is not equal to 3
confermano una distribuzione gaussiana della variabile y.
Anche un test globale per la normalità
> shapiro.test(x) # test di Shapiro-Wilk
Shapiro-Wilk normality test
data: x
W = 0.93397, p-value = 0.4524
> shapiro.test(y)
Shapiro-Wilk normality test
data: y
W = 0.91105, p-value = 0.2509
conferma che le due variabili sono distribuite in modo gaussiano.
Integriamo i test statistici con un semplice grafico xy dei dati realizzato mediante la funzione plot(). Da notare che gli argomenti che definiscono limite inferiore e limite superiore dell'asse delle x (xlim) e dell'asse delle y (ylim) sono parametrizzati, nel senso che ricavano valore minimo (min(x) e min(y)) e valore massimo (max(x) e max(y)) impiegati nel grafico dai dati in ingresso, in modo che cambiando i dati le scale degli assi siano automaticamente riadattate. Ma nulla impedisce di sostituire tali valori di volta in volta con valori numerici fissi che possono fornire una miglior rappresentazione del grafico (in questo caso ad esempio sarebbe più appropriato dimensionare entrambi gli assi tra da 0 a 100).
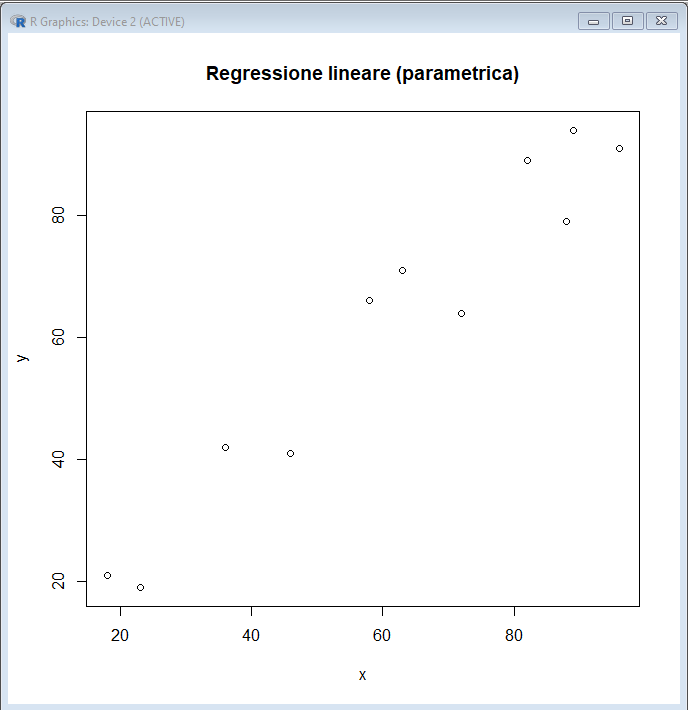
A questo punto sappiamo di avere:
→ due variabili che i test statistici ci indicano avere una distribuzione gaussiana;
→ un grafico che ci indica che tra le due sussiste, nell'ambito dei valori osservati, una relazione lineare.
Pertanto abbiamo quanto ci serve per essere autorizzati a:
→ riportare la correlazione tra le due variabili sotto forma del coefficiente di correlazione lineare r di Pearson;
→ descrivere la relazione di funzione che collega le due variabili mediante l'equazione della retta di regressione.
L'equazione della retta viene calcolata con il tradizionale metodo parametrico (dei minimi quadrati) come lm(y~x) [3] e il coefficiente di correlazione r viene calcolato come cor(x, y, method="pearson"). L'intercetta a e il coefficiente angolare b della retta di regressione sono impiegati per riportarla mediante la funzione lines() nel grafico, che viene infine completato aggiungendo mediante la funzione legend() una legenda che riporta l'equazione della retta e il coefficiente di correlazione r.

Lo script si chiude ripristinando l'espressione dei numeri in formato esponenziale con options(scipen=0).
Vediamo ora cosa accade fare quando i dati non sono distribuiti normalmente e quindi viene impiegato il coefficiente di correlazione per ranghi ρ (rho) di Spearman (test non parametrico) e viene rappresentata la retta di regressione lineare non parametrica.
Copiate e incollate nella Console di R lo script, che ricalca il precedente, e premete ↵ Invio:
# Coefficiente di correlazione per ranghi ρ (rho) di Spearman e regressione lineare non parametrica di Siegel
#
x <- c(18, 16, 19, 12, 17, 13, 15, 58, 64, 36, 82, 88) # variabile in ascisse
y <- c(21, 14, 15, 11, 20, 18, 19, 46, 38, 42, 89, 79) # variabile in ordinate
#
# coefficienti di correlazione
#
options(scipen=999) # predispone espressione dei numeri in formato fisso
cor.test(x, y, method="pearson") # r di Pearson
cor.test(x, y, method="spearman") # ρ (rho) di Spearman
cor.test(x, y, method="kendall") # τ (tau) di Kendall
#
# test di gaussianità
#
library(moments) # carica il pacchetto
agostino.test(x) # test di D'Agostino per il coefficiente di asimmetria di x
anscombe.test(x) # test di Anscombe-Glynn per il coefficiente di curtosi
#
agostino.test(y) # test di D'Agostino per il coefficiente di asimmetria di y
anscombe.test(y) # test di Anscombe-Glynn per il coefficiente di curtosi
#
shapiro.test(x) # test di Shapiro-Wilk
shapiro.test(y)
#
# grafico xy
#
plot(x, y, xlim = c(min(x), max(x)), ylim = c(min(y), max(y)), main="Regressione lineare di Siegel (non parametrica)")
#
# aggiunge al grafico la regressione lineare non parametrica con ρ (rho) di Spearman
#
library(mblm) # carica il pacchetto per la regressione di Siegel
reglin <- mblm(y ~ x, repeated=TRUE) # calcola la regressione lineare non parametrica di Siegel
a <- reglin$coefficients[1] # intercetta a
b <- reglin$coefficients[2] # coefficiente angolare b
rho <- cor(x, y, method="spearman") # rho di Spearman
#
lines(c(min(x), max(x)), c(a+b*min(x), a+b*max(x)), col="black", lty=2, lwd=1) # traccia la retta di regressione
#
legend(min(x), max(y), legend=c(paste("Intercetta a =", round(a, digits=0)), paste("Coefficiente angolare b =", round(b, digits=3)), paste("Equazione: y =", round(a, digits=0), ifelse(sign(b) == 1, "+", "-"), round(b, digits=3), "· x"), paste("rho di Spearman =", round(rho, digits=3)))) # aggiunge al grafico la legenda
#
options(scipen=0) # ripristina espressione dei numeri in formato esponenziale
#
In questo caso uno dei test indica una significativa non normalità / non gaussianità nei dati (p < 0.05):
> shapiro.test(x) # test di Shapiro-Wilk
Shapiro-Wilk normality test
data: x
W = 0.79299, p-value = 0.007807
> shapiro.test(y)
Shapiro-Wilk normality test
data: y
W = 0.80417, p-value = 0.01045
A questo punto abbiamo:
→ due variabili che non sono adeguatamente distribuite in modo gaussiano;
→ un grafico che ci indica che tra le due, nell'ambito dei valori osservati, sussiste quella che possiamo ancora ragionevolmente ritenere una relazione lineare.
Le indicazioni che dobbiamo seguire sono pertanto:
→ esprimere la correlazione mediante un coefficiente di correlazione non parametrico – in questo caso impieghiamo il coefficiente di correlazione per ranghi ρ (rho) di Spearman;
→ riportare una regressione lineare non parametrica – in questo caso impieghiamo la regressione lineare non parametrica di Siegel [4].
Questo è il grafico generato per presentare in forma sintetica i risultati:

Se preferite in alternativa impiegando gli istessi dati potete esprimere la correlazione mediante il coefficiente di correlazione τ (tau) di Kendall (test non parametrico) e rappresentando sempre la retta di regressione lineare non parametrica [5]. Per farlo copiate e incollate nella Console di R quest'ultimo script e premete ↵ Invio:
# Coefficiente di correlazione τ (tau) di Kendall e regressione lineare non parametrica di Siegel
#
x <- c(18, 16, 19, 12, 17, 13, 15, 58, 64, 36, 82, 88) # variabile in ascisse
y <- c(21, 14, 15, 11, 20, 18, 19, 46, 38, 42, 89, 79) # variabile in ordinate
#
# coefficienti di correlazione
#
options(scipen=999) # predispone espressione dei numeri in formato fisso
cor.test(x, y, method="pearson") # r di Pearson
cor.test(x, y, method="spearman") # ρ (rho) di Spearman
cor.test(x, y, method="kendall") # τ (tau) di Kendall
#
# test di gaussianità
#
library(moments) # carica il pacchetto
agostino.test(x) # test di D'Agostino per il coefficiente di asimmetria di x
anscombe.test(x) # test di Anscombe-Glynn per il coefficiente di curtosi
#
agostino.test(y) # test di D'Agostino per il coefficiente di asimmetria di y
anscombe.test(y) # test di Anscombe-Glynn per il coefficiente di curtosi
#
shapiro.test(x) # test di Shapiro-Wilk
shapiro.test(y)
#
# grafico xy
#
plot(x, y, xlim = c(min(x), max(x)), ylim = c(min(y), max(y)), main="Regressione lineare di Siegel (non parametrica)")
#
# aggiunge al grafico la regressione lineare non parametrica e τ (tau) di Kendall
#
library(mblm) # carica il pacchetto per la regressione di Siegel
reglin <- mblm(y ~ x, repeated=TRUE) # calcola la regressione lineare non parametrica di Siegel
a <- reglin$coefficients[1] # intercetta a
b <- reglin$coefficients[2] # coefficiente angolare b
tau <- cor(x, y, method="kendall") # tau di Kendall
#
lines(c(min(x), max(x)), c(a+b*min(x), a+b*max(x)), col="black", lty=2, lwd=1) # traccia la retta di regressione
#
legend(min(x), max(y), legend=c(paste("Intercetta a =", round(a, digits=0)), paste("Coefficiente angolare b =", round(b, digits=3)), paste("Equazione: y =", round(a, digits=0), ifelse(sign(b) == 1, "+", "-"), round(b, digits=3), "· x"), paste("tau di Kendall =", round(tau, digits=3)))) # aggiunge al grafico la legenda
#
options(scipen=0) # ripristina espressione dei numeri in formato esponenziale
#
La differenza sostanziale rispetto al ρ (rho) di Spearman è un coefficiente di correlazione τ (tau) di Kendall che risulta meno significativo, come previsto per un test più conservativo. Questo è il grafico che illustra in forma sintetica i risultati.

La conclusione?
Non è vero che ricercare una correlazione equivale semplicemente a calcolare il coefficiente di correlazione lineare r e la sua significatività.
Infatti è necessario ricordare i princìpi generali soggiacenti alla correlazione:
→ uno studio di correlazione ha un senso solamente quando sia supportato da un modello di un evento – fisico, chimico-fisico, biologico, fisiologico, econometrico o quant'altro – che si assume spieghi e descriva adeguatamente la relazione di funzione che intercorre tra le variabili;
→ è indispensabile verificare che gli assunti alla base del modello di correlazione impiegato siano rispettati;
→ esistono alternative al coefficiente di correlazione lineare r che è necessario utilizzare quando detti assunti non sono rispettati;
→ correlazione statisticamente significativa non significa causazione [6], l'assunzione implicita di un rapporto di causa-effetto in seguito ad un coefficiente di correlazione significativo è una delle trappole subdola e ricorrente nella statistica [7].
Nonostante questi limiti, in R sono disponibili gli strumenti che, impiegati in modo appropriato, possono fornire un valido aiuto quando si vogliono analizzare i dati alla ricerca di una possibile correlazione, che in ogni caso va interpretata con attenzione, cautela e spirito critico.
----------
[1] Cerco per quanto possibile di evitare l'aggettivo "normale" in quanto viene impiegato con troppi differenti significati: la distribuzione cui ci si riferisce è a rigore la "distribuzione gaussiana".
[2] Trovate i relativi manuali in: Available CRAN Packages By Name.
https://cran.r-project.org/web/packages/available_packages_by_name.html
[3] Per i dettagli sull'impiego della funzione e sulla rappresentazione della retta vedere i post La regressione lineare: assunti e modelli e il post Regressione lineare semplice parametrica.
[4] Due altri metodi per il calcolo della regressione lineare non parametrica, alternativi a quello di Siegel, sono riportati nel post Regressione lineare semplice non parametrica.
[5] In realtà i modelli di regressione qui impiegati, parametrici e non parametrici, prevedono tutti che x sia la variabile indipendente mentre i dati reali che si intende analizzare potrebbero non rispettare questo assunto. Per questo tema, e per i modelli di regressione lineare alternativi che devono essere presi in considerazione, vedere il post La regressione lineare: assunti e modelli.
[6] “Correlation is not causation”. In: Campbell MJ, Machin D. Medical Statistics. A Commonsense Approach. John Wiley & Sons, New York, 1993, ISBN 0-471-93764-9, p. 103.
[7] Vedere quanto ho già sottolineato nel post Correlazione e causazione.
Nessun commento:
Posta un commento