Nel
post Teorema di Bayes e diagnosi medica
abbiamo
visto che è possibile impiegare il teorema di Bayes per rispondere
alle due domande: quale probabilità ha di essere affetto da una
specifica malattia un soggetto cui un dato test per quella specifica
malattia è risultato positivo? quale probabilità ha di essere sano
un soggetto cui il test è risultato negativo?
E
abbiamo visto come un modo semplice per farlo si basi sul numero di
casi osservati, organizzati come in questa tabella
Malattia
+
|
Malattia
-
|
|
Test
+
|
VP
|
FP
|
Test
-
|
FN
|
VN
|
nella
quale sono definiti come:
→
veri
positivi
(VP)
i soggetti malati
con il test positivo;
→
falsi
positivi
(FP)
i soggetti sani
con il test positivo;
→
falsi
negativi
(FN)
i soggetti malati
con il test negativo;
→ veri
negativi
(VN)
i soggetti sani
con il test negativo.
Nel
post Curve ROC e valore soglia abbiamo visto, dati i risultati di un
test per la diagnosi di una malattia X, come impiegare il pacchetto
pROC
per tracciare la curva ROC [1] e ricavare il
valore
soglia
(Fig.
1d)
che consente
di classificare correttamente il maggior numero possibile di soggetti
sani (VN) e di classificare correttamente il maggior numero possibile
di soggetti malati (VP), minimizzando sia la possibilità di
sbagliare classificando dei soggetti malati come sani (FN) sia la
possibilità di sbagliare classificando dei soggetti sani come malati
(FP). Fissato il valore soglia, risultano determinate la
sensibilità
e la specificità
del test.
Nel
post Sensibilità, specificità e valore predittivo abbiamo impiegato
il pacchetto epiR per calcolare le probabilità che rispondono
alle due domande:
→ il valore predittivo di un test positivo,
ovvero la probabilità di essere malato per un soggetto che presenta
un test positivo, che risponde alla prima domanda;
→ il valore
predittivo di un test negativo, ovvero la probabilità di essere
sano per un soggetto che presenta un test negativo, che risponde alla
seconda domanda.
In
questo post, che conclude la saga bayesiana, impieghiamo R
per completare quanto visto finora
con una analisi numerica e una analisi grafica dettagliate [2] dei
dati del file
bayes.csv
[3].
Nel
primo passaggio, impiegando il pacchetto ROCR, sono calcolati, per ciascuno dei possibili valori soglia compresi tra
il valore minimo e il valore massimo osservati, il numero di VP, FP,
FN e VN. Nel secondo passaggio, impiegando semplicemente le funzioni
base di R, sono calcolati e rappresentati graficamente, per ciascuno dei
possibili valori soglia compresi tra il valore minimo e il valore
massimo osservati, sensibilità, specificità, efficienza
diagnostica, valore predittivo del test positivo, valore predittivo
del test negativo e accuratezza diagnostica.
Per
proseguire è necessario:
→
effettuare
il download del file bayes.csv
→
salvare
il file nella cartella
C:\Rdati\
Trovate il file, con le istruzioni per scaricare questo e gli altri file di dati impiegati nei post, alla pagina Dati.
classe;valore
0;19
0;22
0;26
0;28
0;29
.....
1;235
1;237
1;237
1;242
1;242
Inoltre
il pacchetto aggiuntivo ROCR [4] deve essere scaricato dal
CRAN. Copiate questo script,
incollatelo nella Console
di R e premete ↵
Invio:
#
EFFICIENZA E ACCURATEZZA DIAGNOSTICA
#
library(ROCR)
# carica il pacchetto
mydata
<- read.table("c:/Rdati/bayes.csv", header=TRUE,
sep=";") #
importa i dati
attach(mydata)
# consente di impiegare direttamente i nomi delle variabili
#
#
calcola sensibilità, specificità, valore predittivo
#
pred
<- prediction(valore, classe)
# genera mediante la funzione prediction() un oggetto che contiene una pre-elaborazione dei dati
#
cut
<- sort(unlist(pred@cutoffs), decreasing=FALSE)
# calcola i valori soglia
vp
<- sort(unlist(pred@tp), decreasing=TRUE)
# calcola i veri positivi
fp
<- sort(unlist(pred@fp), decreasing=TRUE)
# calcola i falsi positivi
fn
<- sort(unlist(pred@fn), decreasing=FALSE)
# calcola i falsi negativi
vn
<- sort(unlist(pred@tn), decreasing=FALSE)
# calcola i veri negativi
#
tabpred
<- data.frame(cut, vp, fp, fn, vn)
# genera la tabella con i valori calcolati
names(tabpred)
<- c("cutoff", "VP", "FP", "FN",
"VN") #
assegna i nomi alle variabili/colonne
tabpred
# mostra la tabella
#
sens
<- vp/(vp+fn) # calcola la sensibilità per ciascun valore
soglia
spec
<- vn/(vn+fp) #
calcola la specificità per ciascun valore soglia
effi
<- sens*spec #
calcola la efficienza diagnostica per ciascun valore soglia
vptp
<- vp/(vp+fp) #
calcola il valore predittivo del test positivo per ciascun valore soglia
vptn
<- vn/(vn+fn) #
calcola il valore predittivo del test negativo per ciascun valore soglia
accu
<- (vp+vn)/(vp+fp+fn+vn)
# calcola la accuratezza diagnostica per ciascun valore soglia
#
tabprob
<- data.frame(cut, sens, spec, effi, vptp, vptn, accu)
# genera la tabella con i valori calcolati
names(tabprob)
<- c("cutoff", "sensibilità", "specificità",
"efficienza", "vptp", "vptn",
"accuratezza")
# assegna i nomi alle variabili/colonne
tabprob
# mostra la tabella
#
paste("Massima
efficienza diagnostica ", round(max(effi), digits=3), " per
un valore soglia di ", cut[which.max(effi)], sep="")
# riporta la massima efficienza diagnostica e il corrispondente
valore soglia
paste("Massima
accuratezza diagnostica ", round(max(accu), digits=3), "
per un valore soglia di ", cut[which.max(accu)], sep="")
# riporta la massima accuratezza diagnostica e il corrispondente
valore soglia
#
#
traccia istogrammi con curve di sensibilità, specificità ed
efficienza diagnostica
#
sani
<- subset(valore, classe==0)
# sottoinsieme con i valori dei soggetti sani per tracciare gli
istogrammi
malati
<- subset(valore, classe==1)
# sottoinsieme con i valori dei soggetti malati per tracciare gli
istogrammi
#
windows()
# apre una nuova finestra
par(mar=c(5,4,4,5)+.1)
# margini per fare spazio alla scala dell'asse delle y sulla destra
#
hist(malati,
xlim=c(0,250), ylim=c(0,150), xaxp = c(0, 250, 5), yaxp = c(0, 150,
3), breaks=seq(from=0, to=250, by=5), border="red",
col="red", density = 20, angle = 45, main="Sensibilità,
specificità, efficienza diagnostica", xlab="Risultato del
test", ylab="Frequenza", freq=TRUE, plot=TRUE)
# traccia istogramma malati
hist(sani,
xlim=c(0,250), breaks=seq(from=0, to=250, by=5), border="green4",
col="lightgreen", density = 20, angle = -45, freq=TRUE,
add=TRUE, plot=TRUE) #
sovrappone istogramma sani
#
par(new=TRUE)
# sovrappone curva sensibilità
plot(cut,
sens, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=1, lwd=2, pch= 20, cex=0.5, col="blue", xaxt="n",
yaxt="n", xlab="", ylab="")
# traccia la curva
axis(4)
# riporta un secondo asse delle y sulla destra per i valori di
probabilità
mtext("Probabilità
p", side=4, line=3)
# aggiunge la legenda all'asse delle y di destra
#
par(new=TRUE)
# sovrappone curva specificità
plot(cut,
spec, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=1, lwd=2, pch=20, cex=0.5, col="mediumorchid",
xaxt="n", yaxt="n", xlab="", ylab="")
# traccia la curva
#
par(new=TRUE)
# sovrappone curva efficienza diagnostica
plot(cut,
effi, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=3, lwd=2, pch=20, cex=0.5, col="orange", xaxt="n",
yaxt="n", xlab="", ylab="")
# traccia la curva
#
legend(140,
0.97, legend=c("Sani", "Malati", "Sensibilità",
"Specificità", "Efficienza diagnostica"),
col=c("green", "red", "blue",
"mediumorchid", "orange"), lty=c(1,1,1,1,3),
lwd=c(1,1,2,2,2), cex=0.7)
# aggiunge al grafico la legenda
#
#
traccia istogrammi con curve di valore predittivo ed accuratezza
diagnostica
#
windows()
# apre una nuova finestra
par(mar=c(5,4,4,5)+.1)
# margini per fare spazio alla scala dell'asse delle y sulla destra
#
hist(malati,
xlim=c(0,250), ylim=c(0,150), xaxp = c(0, 250, 5), yaxp = c(0, 150,
3), breaks=seq(from=0, to=250, by=5), border="red",
col="red", density = 20, angle = 45, main="Valore
predittivo del test, accuratezza diagnostica", xlab="Risultato
del test", ylab="Frequenza", freq=TRUE, plot=TRUE)
# traccia istogramma malati
hist(sani,
xlim=c(0,250), breaks=seq(from=0, to=250, by=5), border="green4",
col="lightgreen", density = 20, angle = -45, freq=TRUE,
add=TRUE, plot=TRUE) #
sovrappone istogramma sani
#
par(new=TRUE)
# sovrappone curva valore predittivo del test positivo
plot(cut,
vptp, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=1, lwd=2, pch= 20, cex=0.5, col="blue", xaxt="n",
yaxt="n", xlab="",ylab="")
# traccia la curva
axis(4)
# riporta l'asse delle y sulla destra
mtext("Probabilità
p", side=4, line=3)
# aggiunge legenda asse y
#
par(new=TRUE)
# sovrappone curva valore predittivo del test negativo
plot(cut,
vptn, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=1, lwd=2, pch=20, cex=0.5, col="mediumorchid",
xaxt="n", yaxt="n", xlab="", ylab="")
# traccia la curva
#
par(new=TRUE)
# sovrappone curva accuratezza diagnostica
plot(cut,
accu, xlim=c(0,250), ylim=c(0,1), yaxp=c(0,1,5), type="l",
lty=3, lwd=2, pch=20, cex=0.5, col="orange", xaxt="n",
yaxt="n", xlab="", ylab="")
# traccia la curva
#
legend(135,
0.98, legend=c("Sani", "Malati", "Valore
predittivo del test +", "Valore predittivo del test -",
"Accuratezza diagnostica"), col=c("green", "red",
"blue", "mediumorchid", "orange"),
lty=c(1,1,1,1,3), lwd=c(1,1,2,2,2), cex=0.7)
# aggiunge al grafico la legenda
#
Importare
ed elaborare i vostri dati con questo script risulterà semplicissimo: dovete
solamente strutturare i dati come nel file
bayes.csv [5] quindi modificare opportunamente il nome e la
posizione del file nella prima riga di codice.
Con
le prime tre righe di codice viene caricato il pacchetto, sono
importati i dati, e viene reso possibile con la funzione attach()
impiegare direttamente i nomi delle variabili.
La
riga di codice cruciale è la quarta, che salva nell'oggetto
pred
i dati generati dalla funzione
prediction()
del pacchetto ROCR
e precisamente il vettore che contiene tutti i possibili valori
soglia (pred@cutoffs)
e i vettori che riportano per ciascun valore soglia:
→ i
veri positivi
(pred@tp)
→ i
falsi positivi
(pred@fp)
→ i
falsi negativi
(pred@fn)
→ i
veri negativi
(pred@tn).
Questi
cinque vettori sono quindi combinati nella tabella tabpred
che così vi apparirà:
cutoff VP FP FN VN
1 19 843 853 0 0
2 22 843 852 0 1
3 26 843 851 0 2
4 28 843 850 0 3
..........
49 73 771 55 72 798
50 74 766 48 77 805
51 75 763 44 80 809
52 76 760 42 83 811
53 77 755 39 88 814
201 237 4 0 839 853
202 242 2 0 841 853
203 Inf 0 0 843 853
1 19 843 853 0 0
2 22 843 852 0 1
3 26 843 851 0 2
4 28 843 850 0 3
..........
49 73 771 55 72 798
50 74 766 48 77 805
51 75 763 44 80 809
52 76 760 42 83 811
53 77 755 39 88 814
.........
200 235 6 0 837 853201 237 4 0 839 853
202 242 2 0 841 853
203 Inf 0 0 843 853
Pertanto
fissando ad esempio il valore soglia (cutoff) tra sani e malati a
75 avremo
763 VP,
44 FP,
80 FN e
809 VN, e così via.
Nelle
righe successive a partire dai vettori vp,
fp, fn
e vn sono calcolati per
ciascuno dei valori soglia (cutoff) individuati:
→ sensibilità
= VP/(VP+FN)
→ specificità
= VN/(VN+FP)
→ efficienza
diagnostica = sensibilità ·
specificità
→ valore
predittivo del test positivo = VP/(VP+FP)
→ valore
predittivo del test negativo = VN/(VN+FN)
→ accuratezza
diagnostica = (VP+VN)/(VP+FP+FN+VN)
quindi
i vettori sens, spec,
effi, vptp,
vptn, accu
che contengono i dati calcolati sono combinati nella tabella tabprob:
1 19 1.000000000 0.000000000 0.000000000 0.4970519 NaN 0.4970519
2 22 1.000000000 0.001172333 0.001172333 0.4973451 1.0000000 0.4976415
3 26 1.000000000 0.002344666 0.002344666 0.4976387 1.0000000 0.4982311
4 28 1.000000000 0.003516999 0.003516999 0.4979327 1.0000000 0.4988208
.........
49 73 0.914590747 0.935521688 0.855619480 0.9334140 0.9172414 0.9251179
50 74 0.908659549 0.943728019 0.857527476 0.9410319 0.9126984 0.9262972
51 75 0.905100830 0.948417351 0.858413331 0.9454771 0.9100112 0.9268868
52 76 0.901542112 0.950762016 0.857151996 0.9476309 0.9071588 0.9262972
53 77 0.895610913 0.954279015 0.854662700 0.9508816 0.9024390 0.9251179
.........
200 235 0.007117438 1.000000000 0.007117438 1.0000000 0.5047337 0.5064858201 237 0.004744958 1.000000000 0.004744958 1.0000000 0.5041371 0.5053066
202 242 0.002372479 1.000000000 0.002372479 1.0000000 0.5035419 0.5041274
203 Inf 0.000000000 1.000000000 0.000000000 NaN 0.5029481 0.5029481
Da
questa tabella sono ricavati il valore soglia che corrisponde alla
massima efficienza diagnostica
[1]
"Massima efficienza diagnostica 0.858 per un valore soglia di
75"
il valore soglia, identico al precedente, che corrisponde alla
massima accuratezza diagnostica
[1]
"Massima accuratezza diagnostica 0.927 per un valore soglia di
75"
e i valori delle grandezze (sensibilità, specificità, valori predittivi) corrispondenti al valore soglia 75 così individuato.
e i valori delle grandezze (sensibilità, specificità, valori predittivi) corrispondenti al valore soglia 75 così individuato.
Da
notare nelle funzioni paste() che
generano le due righe gli argomenti cut[which.max(effi)]
e cut[which.max(accu)]
nei quali la funzione which.max()
restituisce la posizione, all'interno del rispettivo vettore, del
valore massimo di efficienza o di accuratezza, posizione che viene
impiegata per trovare nel vettore cut
il valore soglia corrispondente. Scorrendo i dati della tabella è
facile confermare che sia nel caso dell'efficienza diagnostica sia
nel caso della accuratezza diagnostica il valore soglia “ottimale”
tra sani e malati
è quello che corrisponde al massimo valore trovato di efficienza o
di accuratezza.
Dalla
tabella sono infine generati i grafici che riportano le sei grandezze
calcolate in funzione del valore soglia (cutoff). In questa parte
l'unica cosa un
po' particolare è la funzione subset()
[6] che viene impiegata per generare, dai dati importati, due
sottoinsiemi separati, uno contenente solamente i valori dei soggetti
sani e l'altro
contenente solamente i valori dei soggetti malati, impiegando come
argomenti:
→ il
nome della variabile (valore)
dalla quale si desidera estrarre il sottoinsieme di valori;
→ il
criterio di selezione dei casi da estrarre, laddove classe==0
indica di estrarre i valori per i quali nella variabile classe
è riportato 0 (sano) e laddove classe==1
indica di estrarre i valori per i quali nella variabile classe
è riportato 1 (malato).
Le
funzioni e gli argomenti impiegati per costruire gli istogrammi con
le distribuzioni dei risultati nel test nei sani e nei malati, e per
sovrapporre ad essi le curve che rappresentano, in funzione dei
valori soglia riportati in ascisse, la sensibilità, la
specificità e l'efficienza diagnostica, sono
illustrati sia nella documentazione di R delle funzioni hist()
e plot() sia nei vari post
dedicati alla rappresentazione grafica dei dati [7], ai quali si
rimanda. Questo è il grafico risultante

Questo invece è il grafico che sovrappone agli istogrammi delle distribuzioni dei risultati nel test nei sani e nei malati le curve che rappresentano, in funzione dei valori soglia riportati in ascisse, il valore predittivo del test positivo, il valore predittivo del test negativo e l'accuratezza diagnostica
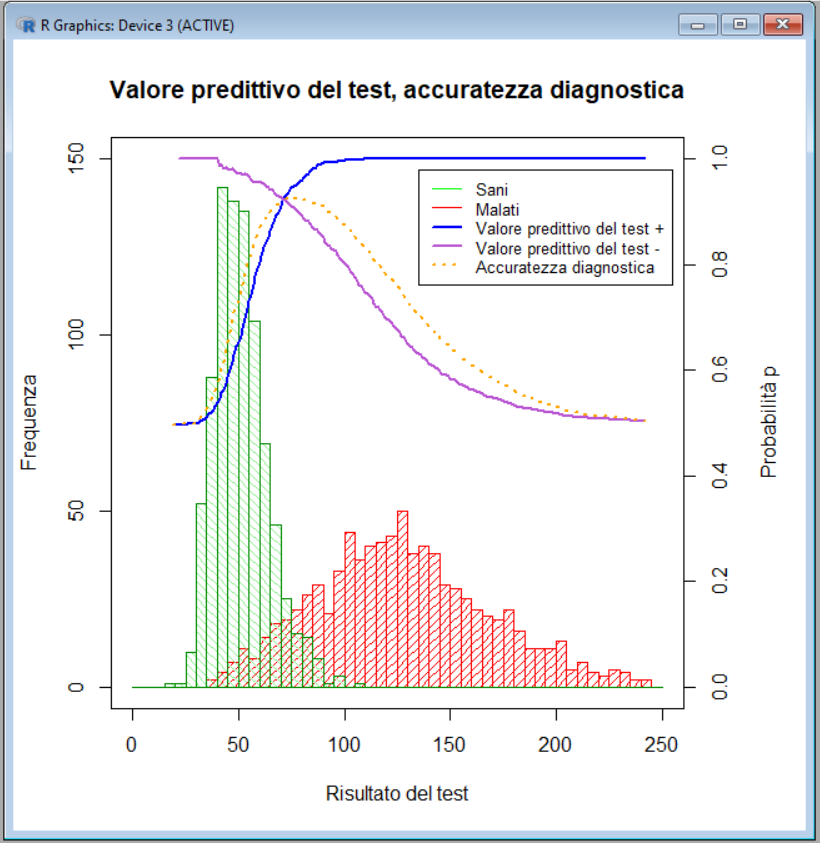
La conclusione è che un'analisi completa e dettagliata, sia numerica sia grafica, delle caratteristiche di un test per la diagnosi di una malattia, esempio paradigmatico di applicazione del teorema di Bayes, può essere realizzata a partire semplicemente dai conteggi di VP, FP, FN e VN effettuati per una serie opportuna di valori soglia, come magistralmente illustrato da Gerhardt e da Keller oltre trent'anni fa [2].
Per una versione che impiega per i calcoli le sole funzioni base di R e che impiega al posto degli istogrammi i kernel density plot, vedere il post Efficienza e accuratezza diagnostica [2].
Se strutturate i vostri dati seguendo le semplici indicazioni riportate sopra, per riutilizzare lo script dovete solamente, nella prima riga di codice, sostituire c:/Rdati/bayes.csv con posizione e nome del vostro file di dati.
----------
[1]
Abbiamo anche visto in un altro post come realizzare due Curve ROC sovrapposte.
[2]
Gerhardt W, Keller H. Evaluation of test data from clinical
studies. Scand J Clin Lab Invest, 46, 1986 (supplement 181).
https://www.tandfonline.com/doi/pdf/10.1080/00365518709168461
[3]
L'esempio qui impiegato rappresenta la situazione più frequente,
quella nella quale la malattia determina un aumento del risultato dei
test, ma ovviamente è sufficiente ribaltare dati e conclusioni per
riadattare il tutto a un caso nel quale la malattia determina una
diminuzione del risultato del test.
[4]
Package ‘ROCR’.
https://cran.r-project.org/web/packages/ROCR/ROCR.pdf
[5]
Vedere il post Curve Roc e valore soglia.
[6]
Digitate help(subset) nella
Console di R per la documentazione della funzione subset().
[7]
Per la funzione legend()
consultare anche il post Aggiungere la legenda a un grafico.
Nessun commento:
Posta un commento